Suppose you have a tester who finds 20 bugs in your program. You want to estimate how many bugs are really in the program. You know there are at least 20 bugs, and if you have supreme confidence in your tester, you may suppose there are around 20 bugs. But maybe your tester isn't very good. Maybe there are hundreds of bugs. How can you have any idea how many bugs there are? There’s no way to know with one tester. But if you have two testers, you can get a good idea, even if you don’t know how skilled the testers are.Then he presents the Lincoln index, an estimator "described by Frederick Charles Lincoln in 1930," where Wikpedia's use of "described" is a hint that the index is another example of Stigler's law of eponymy.
Suppose two testers independently search for bugs. Let k1 be the number of errors the first tester finds and k2 the number of errors the second tester finds. Let c be the number of errors both testers find. The Lincoln Index estimates the total number of errors as k1 k2 / c [I changed his notation to be consistent with mine].So if the first tester finds 20 bugs, the second finds 15, and they find 3 in common, we estimate that there are about 100 bugs.
Of course, whenever I see something like this, the idea that pops into my head is that there must be a (better) Bayesian solution! And there is. You can read and download my solution here.
I represent the data using the tuple (k1, k2, c), where k1 is the number of bugs found by the first tester, k2 is the number of bugs found by the second, and c is the number they find in common.
The hypotheses are a set of tuples (n, p1, p2), where n is the actual number of errors, p1 is the probability that the first tester finds any given bug, and p2 is the probability for the second tester.
Now all I need is a likelihood function:
class Lincoln(thinkbayes.Suite, thinkbayes.Joint):
def Likelihood(self, data, hypo):
"""Computes the likelihood of the data under the hypothesis.
hypo: n, p1, p2
data: k1, k2, c
"""
n, p1, p2 = hypo
k1, k2, c = data
part1 = choose(n, k1) * binom(k1, n, p1)
part2 = choose(k1, c) * choose(n-k1, k2-c) * binom(k2, n, p2)
return part1 * part2
Where choose evaluates the binomial coefficient,
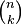 , and binom evaluates the rest of the binomial pmf:
, and binom evaluates the rest of the binomial pmf:def binom(k, n, p):
return p**k * (1-p)**(n-k)
And that's pretty much it. Here's the code that builds and updates the suite of hypotheses:
data = 20, 15, 3
probs = numpy.linspace(0, 1, 101)
hypos = []
for n in range(32, 350):
for p1 in probs:
for p2 in probs:
hypos.append((n, p1, p2))
suite = Lincoln(hypos)
suite.Update(data)
The suite contains the joint posterior distribution for (n, p1, p2), but p1 and p2 are nuisance parameters; we only care about the marginal distribution of n. Lincoln inherits Marginal from Joint, so we can get the marginal distribution like this:
n_marginal = suite.Marginal(0)
Where 0 is the index of n in the tuple. And here's what the distribution looks like:

The lower bound is 32, which is the total number of bugs found by the two testers. I set the upper bound at 350, which chops off a little bit of the tail.
The maximum likelihood estimate in this distribution is 72; the mean is 106. So those are consistent with the Lincoln index, which is 100. But as usual, it is more useful to have the whole posterior distribution, not just a point estimate. For example, this posterior distribution can be used as part of a risk-benefit analysis to guide decisions about how much effort to allocate to finding additional bugs.
This solution generalizes to more than 2 testers, but figuring out the likelihood function, and evaluating it quickly, becomes increasingly difficult. Also, as the number of testers increases, so does the number of dimensions in the space of hypotheses. With two testers there are about 350 * 100 * 100 hypotheses. On my non-very-fast desktop computer, that takes about a minute. I could speed it up by evaluating the likelihood function more efficiently, but each new tester would multiply the run time by 100.
The library I used in my solution is thinkbayes.py, which is described in my book, Think Bayes. Electronic copies are available under a Creative Commons licence from Green Tea Press. Hard copies are published by O'Reilly Media and available from Amazon.com and other booksellers.
I believe that the approach to Bayesian statistics I present in Think Bayes is a good way to solve problems like this. I cite as evidence that this example, from the time I read John's article, to the time I pressed "Publish" on this post, took me about 3 hours.
Thanks for this interesting post.
ReplyDeleteI have implemented your model in BUGS and the mean results were n=106 (like your solution), p1=0.22, p2=0.17. However, the MLE estimate that I got is 77, which is a bit far from your 72 estimate. The prior for n must have been different (I used a truncated exponential with very low lambda) but even so it seems a big difference.
The code and results are here: http://www.di.fc.ul.pt/~jpn/r/bugs/lincoln.html
Cheers,
That's excellent -- thanks!
DeleteMy results are based on a uniform prior for n, which was an arbitrary choice, not motivated by any background knowledge. That might explain the difference between your results and mine, but I agree with you that it seems like a big difference.
Can you run yours again with a uniform prior on [32, 350]?
Also, how long does your model take to run?
With an uniform prior, the mean for 'n' is 108.9 and the MLE estimate is 78. I think this makes sense, since the uniform gives move probability mass to the upper values, relative to the exponential. However, this result produces even a bigger difference between our results (?)
DeleteThe simulation run took 2 seconds.
I assume that it is a problem with my model, but in my defense the simulation I do at the end for the expected value of 'c' is very near 3 :-) With the exponential the simulated result was 2.98. With the uniform the result was 2.95.
Huh. I'm baffled for now. Let me know if you learn more.
DeleteI found the analytic solution for p(n|data) and the mode is at 72.18 which confirms your result. My result for the mode with the uniform prior is at 75.9. I really don't know what is causing this difference but I suppose it is from my BUGS model. Oh well...
DeleteHuh. Well, let me know if you figure it out.
DeleteWhere did you find the analytic solution?
Well, not 'where' but 'how' :-) I used Mathematica to make the integration and R to find the mode. The details are at the end of the webpage I made.
DeleteCheers,
Just an extra note: I'm learning a bit of Stan and I coded the exact same model as in BUGS. The result after 100k iterations was 72.11. So, another confirmation :-) By some mysterious reason BUGS is having problems dealing with this likelihood function.
DeleteMuch better than the Cooke post. Cooke's post has a flaw - if you send an app to a million beta testers, and 5000 users find a few bugs, your bug count projection spirals high very quickly (since the numerator ultimately becomes an exponential function).
ReplyDeleteI intend to give this a whirl and see what numbers I get.
I think it should be noted that the assumption that all error probabilities are the same makes a big difference. Suppose I have a program with 100 bugs, 5 of which are easy to find, and two testers who are bad at finding bugs. Tester 1 finds 10 bugs (including all 5 easy ones), tester 2 finds 10 bugs (including all 5 easy ones), and the intersection is the 5 easy ones. The Lincoln index would estimate 20 bugs and your method would find something similar (I'm assuming, I didn't implement the code). In general, the more the probabilities differ from error to error, the more these methods will underestimate the total number of errors. They do work quite well, though, when error probabilities are uniform.
ReplyDeleteYes, good point. Thanks!
Delete