I have updated this article with new data, better code, and friendlier data visualization.
You can read the new version here.
The Inspection Paradox is Everywhere
You can read the new version here.
The inspection paradox is a common source of confusion, an occasional source of error, and an opportunity for clever experimental design. Most people are unaware of it, but like the cue marks that appear in movies to signal reel changes, once you notice it, you can’t stop seeing it.
A common example is the apparent paradox of class sizes. Suppose you ask college students how big their classes are and average the responses. The result might be 56. But if you ask the school for the average class size, they might say 31. It sounds like someone is lying, but they could both be right.
The problem is that when you survey students, you oversample large classes. If there are 10 students in a class, you have 10 chances to sample that class. If there are 100 students, you have 100 chances. In general, if the class size is x, it will be overrepresented in the sample by a factor of x.
That’s not necessarily a mistake. If you want to quantify student experience, the average across students might be a more meaningful statistic than the average across classes. But you have to be clear about what you are measuring and how you report it.
By the way, I didn’t make up the numbers in this example. They come from class sizes reported by Purdue University for undergraduate classes in the 2013-14 academic year. https://www.purdue.edu/datadigest/2013-14/InstrStuLIfe/DistUGClasses.html
From the data in their report, I estimate the actual distribution of class sizes; then I compute the “biased” distribution you would get by sampling students. The CDFs of these distributions are in Figure 1.
Going the other way, if you are given the biased distribution, you can invert the process to estimate the actual distribution. You could use this strategy if the actual distribution is not available, or if it is easier to run the biased sampling process.
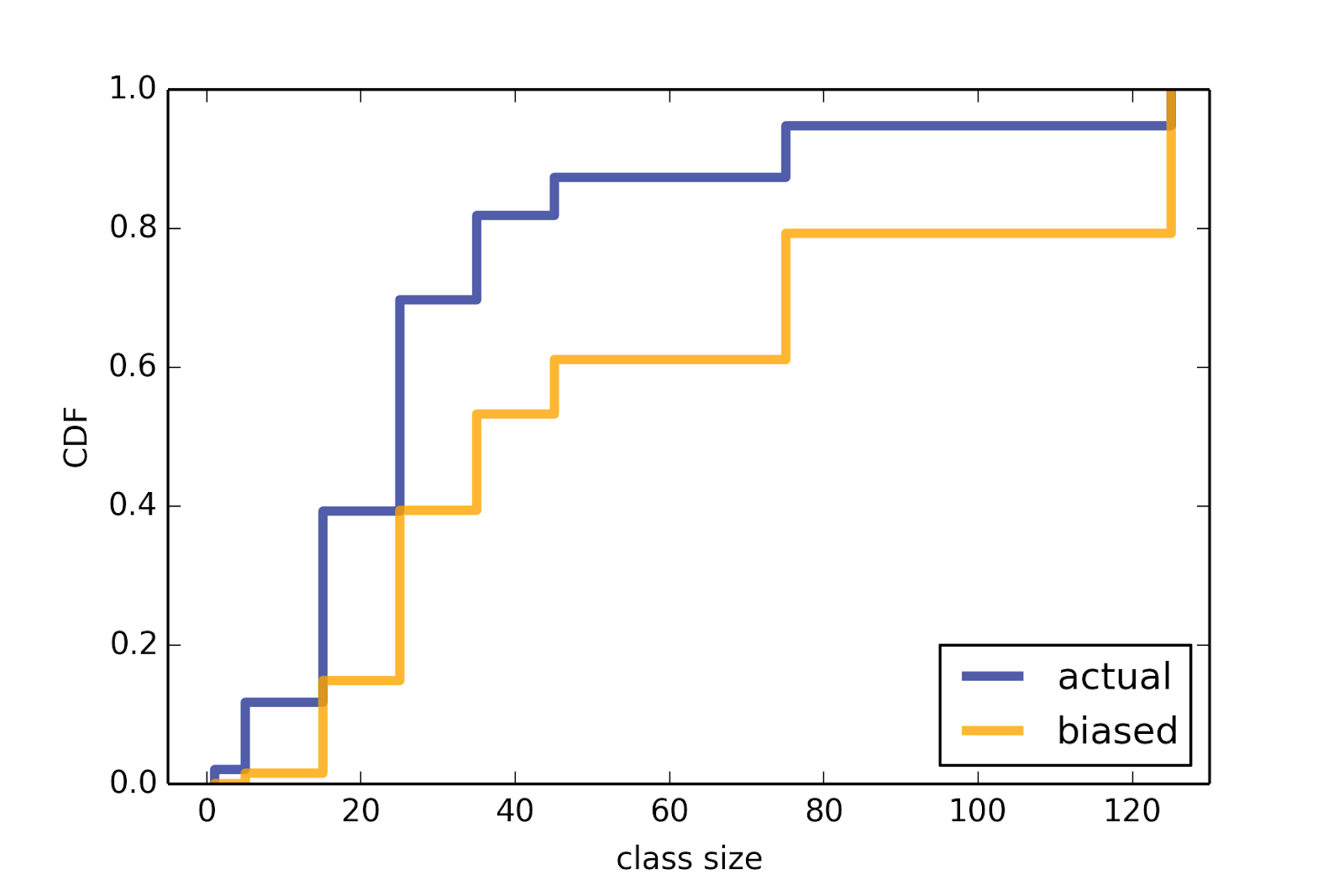
Figure 1: Undergraduate class sizes at Purdue University, 2013-14 academic year: actual distribution and biased view as seen by students.
The same effect applies to passenger planes. Airlines complain that they are losing money because so many flights are nearly empty. At the same time passengers complain that flying is miserable because planes are too full. They could both be right. When a flight is nearly empty, only a few passengers enjoy the extra space. But when a flight is full, many passengers feel the crunch.
Once you notice the inspection paradox, you see it everywhere. Does it seem like you can never get a taxi when you need one? Part of the problem is that when there is a surplus of taxis, only a few customers enjoy it. When there is a shortage, many people feel the pain.
Another example happens when you are waiting for public transportation. Buses and trains are supposed to arrive at constant intervals, but in practice some intervals are longer than others. With your luck, you might think you are more likely to arrive during a long interval. It turns out you are right: a random arrival is more likely to fall in a long interval because, well, it’s longer.
To quantify this effect, I collected data from the Red Line in Boston. Using their real-time data service, I recorded the arrival times for 70 trains between 4pm and 5pm over several days.
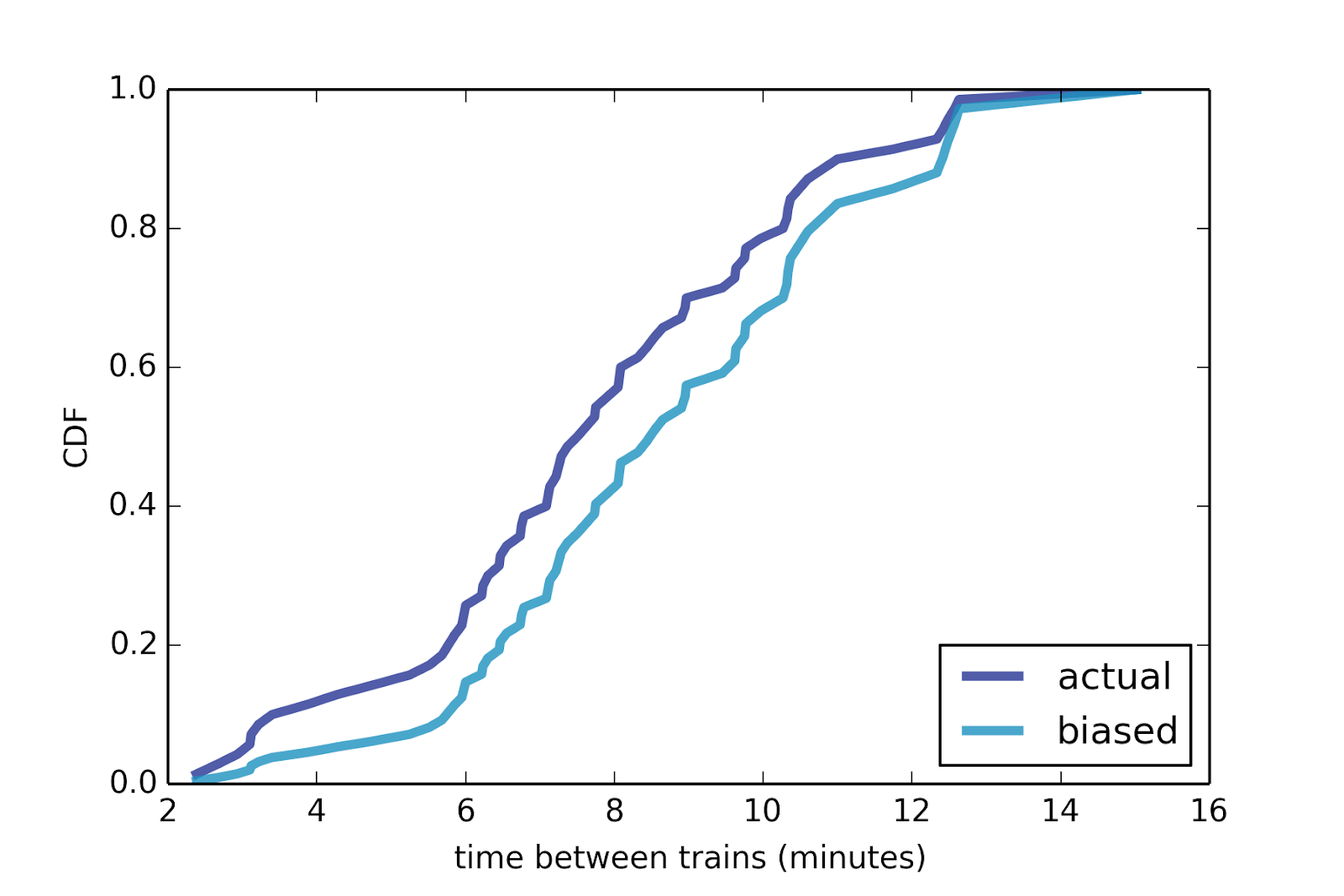
Figure 2: Distribution of time between trains on the Red Line in Boston, between 4pm and 5pm.
The shortest gap between trains was less than 3 minutes; the longest was more than 15. Figure 2 shows the actual distribution of time between trains, and the biased distribution that would be observed by passengers. The average time between trains is 7.8 minutes, so we might expect the average wait time to be 3.8 minutes. But the average of the biased distribution is 8.8 minutes, and the average wait time for passengers is 4.4 minutes, about 15% longer.
In this case the difference between the two distributions is not very big because the variance of the actual distribution is moderate. When the actual distribution is long-tailed, the effect of the inspection paradox can be much bigger.
An example of a long-tailed distribution comes up in the context of social networks. In 1991, Scott Feld presented the “friendship paradox”: the observation that most people have fewer friends than their friends have. He studied real-life friends, but the same effect appears in online networks: if you choose a random Facebook user, and then choose one of their friends at random, the chance is about 80% that the friend has more friends.
The friendship paradox is a form of the inspection paradox. When you choose a random user, every user is equally likely. But when you choose one of their friends, you are more likely to choose someone with a lot of friends. Specifically, someone with x friends is overrepresented by a factor of x.
To demonstrate the effect, I use data from the Stanford Large Network Dataset Collection (http://snap.stanford.edu/data), which includes a sample of about 4000 Facebook users. We can compute the number of friends each user has and plot the distribution, shown in Figure 3. The distribution is skewed: most users have only a few friends, but some have hundreds.
We can also compute the biased distribution we would get by choosing choosing random friends, also shown in Figure 3. The difference is huge. In this dataset, the average user has 42 friends; the average friend has more than twice as many, 91.
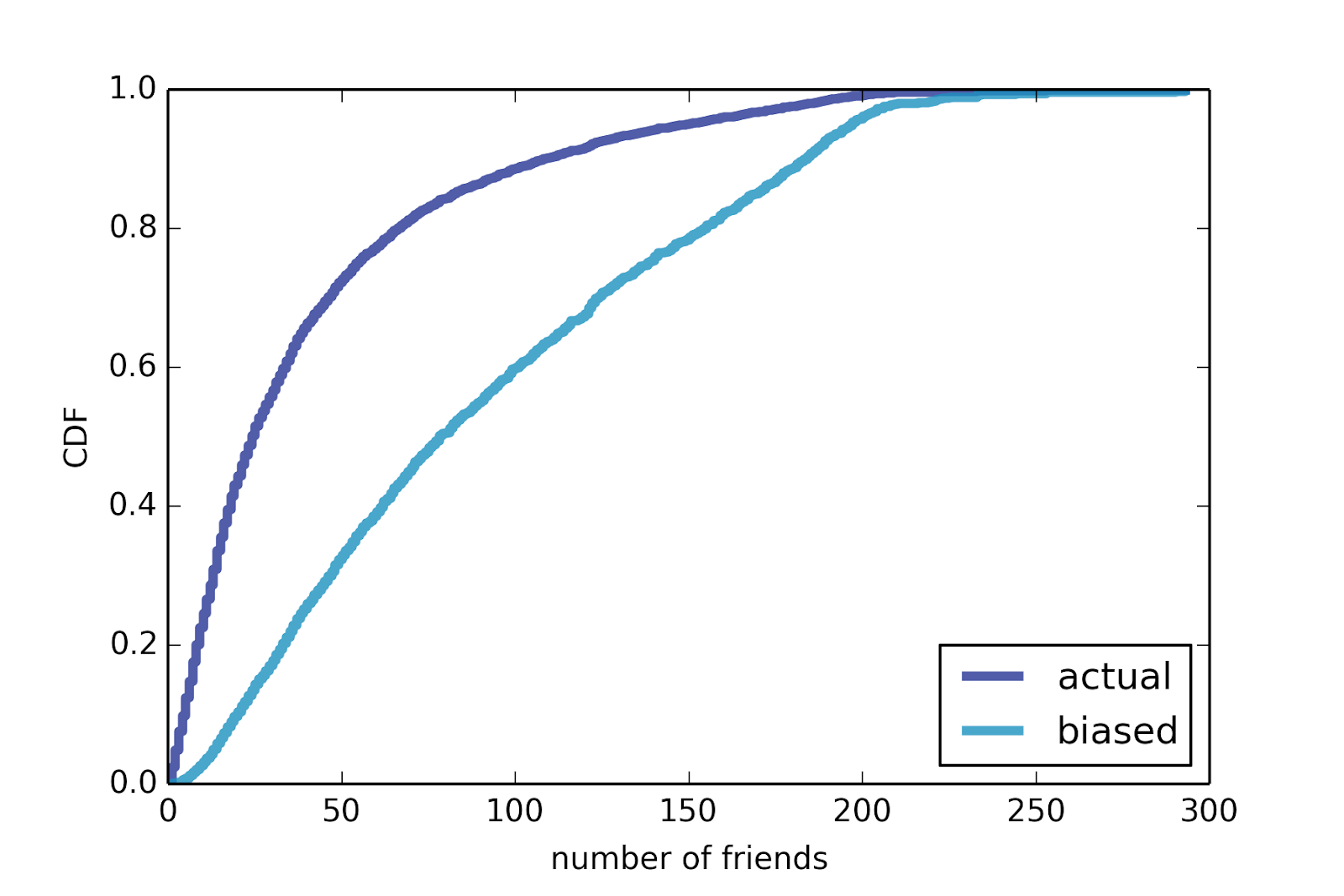
Figure 3: Number of online friends for Facebook users: actual distribution and biased distribution seen by sampling friends.
Some examples of the inspection paradox are more subtle. One of them occurred to me when I ran a 209-mile relay race in New Hampshire. I ran the sixth leg for my team, so when I started running, I jumped into the middle of the race. After a few miles I noticed something unusual: when I overtook slower runners, they were usually much slower; and when faster runners passed me, they were usually much faster.
At first I thought the distribution of runners was bimodal, with many slow runners, many fast runners, and few runners like me in the middle. Then I realized that I was fooled by the inspection paradox.
In many long relay races, teams start at different times, and most teams include a mix of faster and slower runners. As a result, runners at different speeds end up spread over the course; if you stand at random spot and watch runners go by, you see a nearly representative sample of speeds. But if you jump into the race in the middle, the sample you see depends on your speed.
Whatever speed you run, you are more likely to pass very slow runners, more likely to be overtaken by fast runners, and unlikely to see anyone running at the same speed as you. The chance of seeing another runner is proportional to the difference between your speed and theirs.
We can simulate this effect using data from a conventional road race. Figure 4 shows the actual distribution of speeds from the James Joyce Ramble, a 10K race in Massachusetts. It also shows biased distributions that would be seen by runners at 6.5 and 7.5 mph. The observed distributions are bimodal, with fast and slow runners oversampled and fewer runners in the middle.
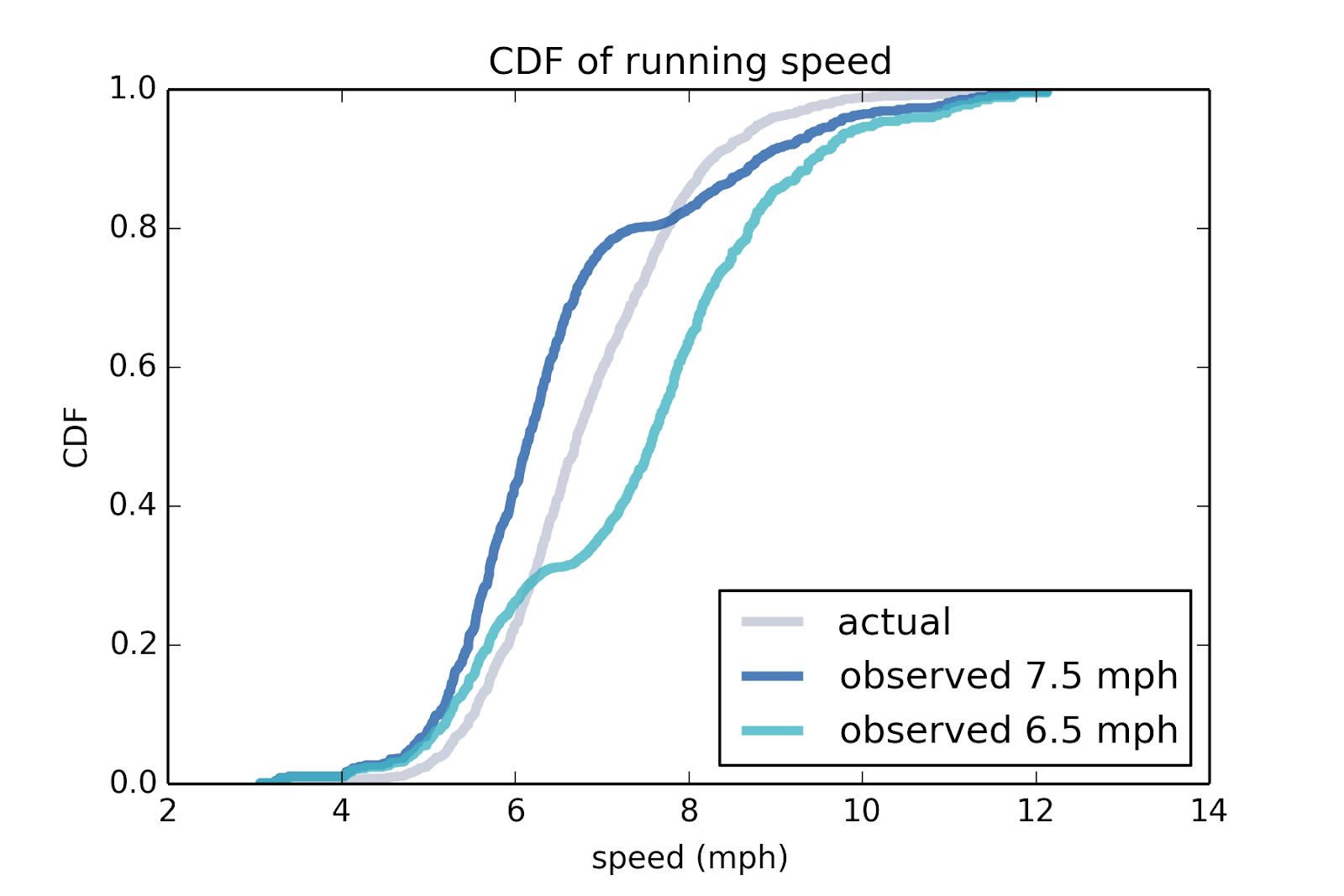
Figure 4: Distribution of speed for runners in a 10K, and biased distributions as seen by runners at different speeds.
A final example of the inspection paradox occurred to me when I was reading Orange is the New Black, a memoir by Piper Kerman, who spent 13 months in a federal prison. At several points Kerman expresses surprise at the length of the sentences her fellow prisoners are serving. She is right to be surprised, but it turns out that she is the victim of not just an inhumane prison system, but also the inspection paradox.
If you arrive at a prison at a random time and choose a random prisoner, you are more likely to choose a prisoner with a long sentence. Once again, a prisoner with sentence x is oversampled by a factor of x.
Using data from the U.S. Sentencing Commission, I made a rough estimate of the distribution of sentences for federal prisoners, shown in Figure 5. I also computed the biased distribution as observed by a random arrival.
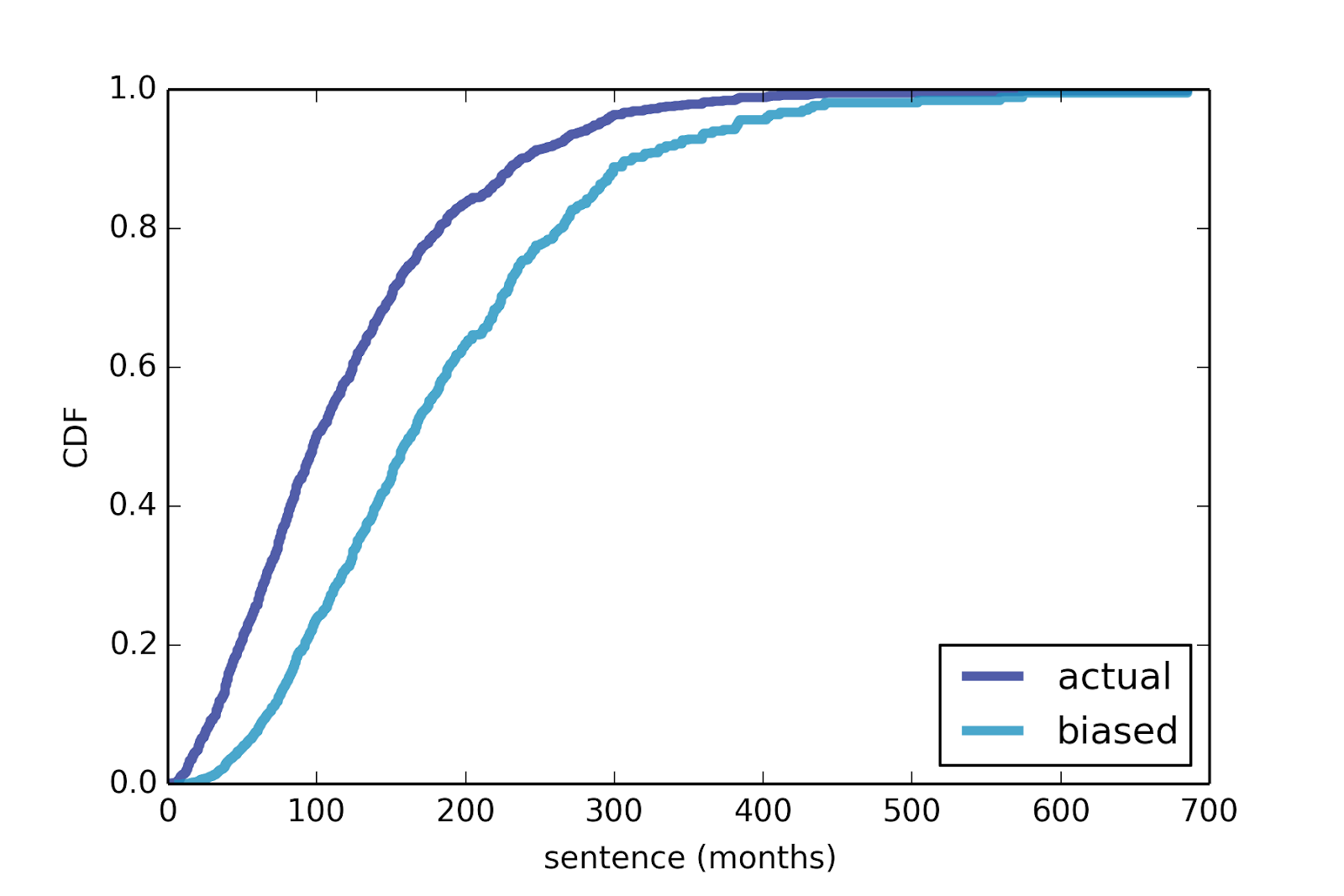
Figure 5: Approximate distribution of federal prison sentences, and a biased distribution as seen by a random arrival.
As expected, the biased distribution is shifted to the right. In the actual distibution the mean is 121 months; in the biased distribution it is 183 months.
So what happens if you observe a prison over an interval like 13 months? It turns out that if your sentence is y months, the chance of overlapping with a prisoner whose sentence is x months is proportional to x + y.
Figure 6 shows biased distributions as seen by hypothetical prisoners serving sentences of 13, 120, and 600 months.
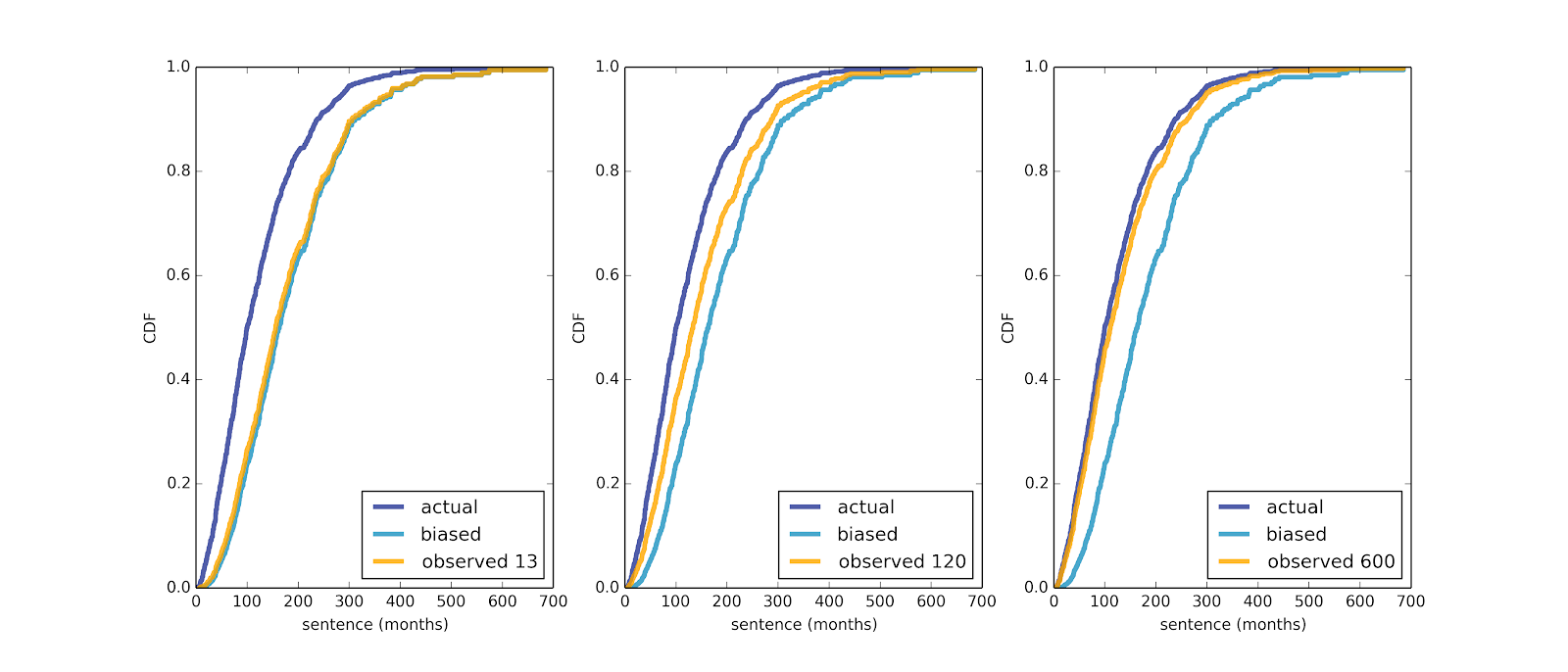
Figure 6: Biased distributions as seen by prisoners with different sentences.
Over an interval of 13 months, the observed sample is not much better than the biased sample seen by a random arrival. After 120 months, the magnitude of the bias is about halved. Only after a very long sentence, 600 months, do we get a more representative sample, and even then it is not entirely unbiased.
These examples show that the inspection paradox appears in many domains, sometimes in subtle ways. If you are not aware of it, it can cause statistical errors and lead to invalid inferences. But in many cases it can be avoided, or even used deliberately as part of an experimental design.
Further reading
I discuss the class size example in my book, Think Stats, 2nd Edition, O’Reilly Media, 2014, and the Red Line example in Think Bayes, O’Reilly Media, 2013. I wrote about relay races, social networks, and Orange Is the New Black in my blog, “Probably Overthinking It”. http://allendowney.blogspot.com/
John Allen Paulos presents the friendship paradox in Scientific American, “Why You're Probably Less Popular Than Your Friends”, 18 January 2011. http://www.scientificamerican.com/article/why-youre-probably-less-popular/
The original paper on the topic might be Scott Feld, “Why Your Friends Have More Friends Than You Do”, American Journal of Sociology, Vol. 96, No. 6 (May, 1991), pp. 1464-1477. http://www.jstor.org/stable/2781907
Amir Aczel discusses some of these examples, and a few different ones, in a Discover Magazine blog article, “On the Persistence of Bad Luck (and Good)”, 4 September 4, 2013.
The code I used to generate these examples is in these Jupyter notebooks:
Bio
Allen Downey is a Professor of Computer Science at Olin College of Engineering in Massachusetts. He is the author of several books, including Think Python, Think Stats, and Think Bayes. He is a runner with a maximum 10K speed of 8.7 mph.
Thanks a lot, very informative, and enjoyable. A minor quibble: I find it easier to comprehend densities rather than cumulative distribution functions. Perhaps I can sway you to illustrate distributions by their pdfs instead of cdfs.
ReplyDeleteI totally understand, and I am sympathetic -- I think most people are more familiar with PDFs than CDFs. But for these examples I have empirical data rather than continuous mathematical models, and in that case using PMFs or estimated PDFs creates a whole bunch of problems that CDFs neatly avoid.
DeleteI decided it was better to use CDFs throughout. But it means the reader has to work a little harder, which I regret.
yeah, the expected class size of a random student is not the sum of the class sizes divided by the number of classes, but rather the sum of the squared class sizes divided by the sum of the class sizes.
Deletegood examples though. another very obvious one is the speed of cars you pass on the highway.
be aware of one limitation to your inversion: by looking at the samples, you cannot determine the number of classes with zero students, so you'll never know the actual average class size.
Good point. Similarly with the relay race example, you can't tell how many runners are the same speed as you.
DeleteMy favorite example (true in many European countries): most families have a single child, but most kids have siblings.
ReplyDeleteEven after having read the article, it took me 10 minutes to figure it out ;)
DeleteGood one. Thanks!
DeleteThis is a fascinating post, thanks.
ReplyDeleteNice post. An example from my own field: The inspection paradox causes most students to get the wrong answer by a factor of 2 in a certain physics calculation, related to electron motion in solids - see http://physics.stackexchange.com/questions/88015/definition-of-mean-free-time-in-the-drude-model/88045#88045
ReplyDeleteAllen, nice article...well-written and easy to understand. One suggestion: use "interarrival time" in the train example instead of "arrival time" because the former is standard queueing parlance. Thanks.
ReplyDeleteHere's something you might want to clarify:
ReplyDelete"when there is a surplus of taxis, only a few customers enjoy it. When there is a shortage, many people feel the pain."
This is true if the number of taxis stays constant and the people vary; but if the number of people stays constant and the taxis vary, it doesn't hold.
Good point. I will revise this and talk about changes of demand rather than supply, which I think will be clearer and avoid the issue you raised.
DeleteIf [there] are 10 students in a class, you have 10 chances to sample that class.
ReplyDelete- great article!
nice piece, thx.
ReplyDeleteWorth reading. I recall when the PC and Windows first hit the business desktop, being dumbfound by users tolerance of the rate at which they crashed.
ReplyDeleteAt the time I was accustomed to mature IBM AS/400 super mini hardware that had an MTBF of about 5 years, and I realized that when PC crashed, it was just one person who was impacted by it, but when the main computer for the whole company crashed, everyone experienced the pain at the same time. Even though the total man-hours a PC was down was orders of magnitude greater than the man-hours the AS/400 was down, the distribution of the pain a little at a time made is seem like less.
Very nice indeed. I shared this via G+ and got a lot of very positive reader feedback on your article as well. (https://plus.google.com/+YonatanZunger/posts/FjCWr1SySQg)
ReplyDeleteOne question: Does it make sense to use PDF's instead of CDF's to illustrate this? With the jogging example (figure 4) in particular, I think a PDF would have highlighted the bimodality far more vividly. (As well as being much more accessible to a non-specialist audience)
Yes, PDFs are definitely easier to read for most people. The problem is that if you have discrete data, you have to smooth the PDFs to see the shape, and if you smooth too much, you obliterate the bimodality. And even if you get it right, it is harder to compare multiple PDFs to see the kind of shifts I want to show.
DeleteBut since several people have asked, I might try again to make PDF-based visualizations for these examples and see if I can make them work.
> Once you notice the inspection paradox, you see it everywhere. Does it seem like you can never get a taxi when you need one?
ReplyDeleteAnd of course, besides buses, taxis, and planes, there's cars: why does the highway so often seem to be jammed? Because if it's jammed, there's a lot more people in it than when it's moving smoothly; I saw this version in Nick Bostrom's http://www.anthropic-principle.com/?q=book/table_of_contents
Which makes me wonder if there is any mode of transportation that the inspection paradox *doesn't* apply to... perhaps when the bucket or lump size equals one and so there is no difference in sampling, like walking or riding your bike or roller skating?
maybe not so many people experience what you say about runners
ReplyDeletebut if you drive long-distance (above an hour) you'll have the same impression about cars on the road "nobody is driving like me, either too slow or too fast"
Good example!
DeleteI wonder how much of the Heuristics and Biases literature in psychology is attributing real biases (like these) to mistakes in the mind!
ReplyDeleteI mostly get this, but what I'm still confused about is the class sizes example. If you have a class size of, say, 15 (according to school admin records) but asking a student they tell you size of 23 - how on earth can they possibly be both right? It's not like the students sit faster or attend a longer class... surely counting a static number by everyone should reveal the same number?? They're not running in class, after all - it's easy to count occupied desks when everyone is seated. Also you did not explain/say/expand what a "CDF" is....
ReplyDeleteThere has to be some variation in class sizes. Suppose there are only two classes, with sizes 1 and 9. The average class size is 5, but the average student report is 8.2.
DeleteFor more about CDFs, see Chapter 4 of Think Stats: http://greenteapress.com/thinkstats2/html/thinkstats2005.html
I must say that's impressive post.
ReplyDelete