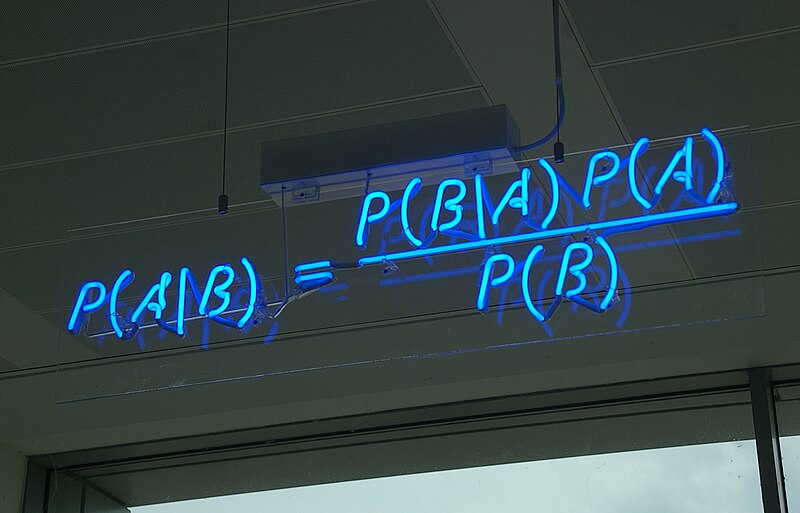
This week's post contains solutions to My Favorite Bayes's Theorem Problems, and one new problem. If you missed last week's post, go back and read the problems before you read the solutions!
If you don't understand the title of this post, brush up on your memes.
1) The first one is a warm-up problem. I got it from Wikipedia (but it's no longer there):
Suppose there are two full bowls of cookies. Bowl #1 has 10 chocolate chip and 30 plain cookies, while bowl #2 has 20 of each. Our friend Fred picks a bowl at random, and then picks a cookie at random. We may assume there is no reason to believe Fred treats one bowl differently from another, likewise for the cookies. The cookie turns out to be a plain one. How probable is it that Fred picked it out of Bowl #1?First the hypotheses:
A: the cookie came from Bowl #1
B: the cookie came from Bowl #2
And the priors:
P(A) = P(B) = 1/2
The evidence:
E: the cookie is plain
And the likelihoods:
P(E|A) = prob of a plain cookie from Bowl #1 = 3/4
P(E|B) = prob of a plain cookie from Bowl #2 = 1/2
Plug in Bayes's theorem and get
P(A|E) = 3/5
You might notice that when the priors are equal they drop out of the BT equation, so you can often skip a step.
2) This one is also an urn problem, but a little trickier.
The blue M&M was introduced in 1995. Before then, the color mix in a bag of plain M&Ms was (30% Brown, 20% Yellow, 20% Red, 10% Green, 10% Orange, 10% Tan). Afterward it was (24% Blue , 20% Green, 16% Orange, 14% Yellow, 13% Red, 13% Brown).
A friend of mine has two bags of M&Ms, and he tells me that one is from 1994 and one from 1996. He won't tell me which is which, but he gives me one M&M from each bag. One is yellow and one is green. What is the probability that the yellow M&M came from the 1994 bag?Hypotheses:
A: Bag #1 from 1994 and Bag #2 from 1996
B: Bag #2 from 1994 and Bag #1 from 1996
Again, P(A) = P(B) = 1/2.
The evidence is:
E: yellow from Bag #1, green from Bag #2
We get the likelihoods by multiplying the probabilities for the two M&M:
P(E|A) = (0.2)(0.2)
P(E|B) = (0.1)(0.14)
For example, P(E|B) is the probability of a yellow M&M in 1996 (0.14) times the probability of a green M&M in 1994 (0.1).
Plugging the likelihoods and the priors into Bayes's theorem, we get P(A|E) = 40 / 54 ~ 0.74
By introducing the terms Bag #1 and Bag #2, rather than "the bag the yellow M&M came from" and "the bag the green came from," I avoided the part of this problem that can be tricky: keeping the hypotheses and the evidence straight.
3) This one is from one of my favorite books, David MacKay's Information Theory, Inference, and Learning Algorithms:
Elvis Presley had a twin brother who died at birth. What is the probability that Elvis was an identical twin?To answer this one, you need some background information: According to the Wikipedia article on twins: ``Twins are estimated to be approximately 1.9% of the world population, with monozygotic twins making up 0.2% of the total---and 8% of all twins.''
There are several ways to set up this problem; I think the easiest is to think about twin birth events, rather than individual twins, and to take the fact that Elvis was a twin as background information.
So the hypotheses are
A: Elvis's birth event was an identical birth event
B: Elvis's birth event was a fraternal twin event
If identical twins are 8% of all twins, then identical birth events are 8% of all twin birth events, so the priors are
P(A) = 8%
P(B) = 92%
The relevant evidence is
E: Elvis's twin was male
So the likelihoods are
P(E|A) = 1
P(E|B) = 1/2
Because identical twins are necessarily the same sex, but fraternal twins are equally likely to be opposite sex (or, at least, I assume so). So
P(A|E) = 8/54 ~ 0.15.
The tricky part of this one is realizing that the sex of the twin provides relevant information!
4) Also from MacKay's book:
Two people have left traces of their own blood at the scene of a crime. A suspect, Oliver, is tested and found to have type O blood. The blood groups of the two traces are found to be of type O (a common type in the local population, having frequency 60%) and of type AB (a rare type, with frequency 1%). Do these data (the blood types found at the scene) give evidence in favour [sic] of the proposition that Oliver was one of the two people whose blood was found at the scene?For this problem, we are not asked for a posterior probability; rather we are asked whether the evidence is incriminating. This depends on the likelihood ratio, but not the priors.
The hypotheses are
X: Oliver is one of the people whose blood was found
Y: Oliver is not one of the people whose blood was found
The evidence is
E: two blood samples, one O and one AB
We don't need priors, so we'll jump to the likelihoods. If X is true, then Oliver accounts for the O blood, so we just have to account for the AB sample:
P(E|X) = 0.01
If Y is true, then we assume the two samples are drawn from the general population at random. The chance of getting one O and one AB is
P(E|Y) = 2(0.6)(0.01) = 0.012
Notice that there is a factor of two here because there are two permutations that yield E.
So the evidence is slightly more likely under Y, which means that it is actually exculpatory! This problem is a nice reminder that evidence that is consistent with a hypothesis does not necessarily support the hypothesis.
5) I like this problem because it doesn't provide all of the information. You have to figure out what information is needed and go find it.
According to the CDC, ``Compared to nonsmokers, men who smoke are about 23 times more likely to develop lung cancer and women who smoke are about 13 times more likely.''I find it helpful to draw a tree:
If you learn that a woman has been diagnosed with lung cancer, and you know nothing else about her, what is the probability that she is a smoker?

Of all women who get lung cancer, the fraction who smoke is 13xy / (13xy + x(1-y)).
The x's cancel, so it turns out that we don't actually need to know the absolute risk of lung cancer, just the relative risk. But we do need to know y, the fraction of women who smoke. According to the CDC, y was 17.9% in 2009. So we just have to compute
13y / (13y + 1-y) ~ 74%
This is higher than many people guess.
6) Next, a mandatory Monty Hall Problem. First, here's the general description of the scenario, from Wikipedia:
Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say Door A [but the door is not opened], and the host, who knows what's behind the doors, opens Door B, which has a goat. He then says to you, "Do you want to pick Door C?" Is it to your advantage to switch your choice?The answer depends on the behavior of the host when the car is behind Door A. In this case the host can open either B or C. Suppose he chooses B with probability p and C otherwise. What is the probability that the car is behind Door A (as a function of p)?
The hypotheses are
A: the car is behind Door A
B: the car is behind Door B
C: the car is behind Door C
And the priors are
P(A) = P(B) = P(C) = 1/3
The likelihoods are
P(E|A) = p, because in this case Monty has a choice and chooses B with probability p,
P(E|B) = 0, because if the car were behind B, Monty would not have opened B, and
P(E|C) = 1, because in this case Monty has no choice.
Applying Bayes's Theorem,
P(A|E) = p / (1+p)
In the canonical scenario, p=1/2, so P(A|E) = 1/3, which is the canonical solution. If p=0, P(A|E) = 0, so you can switch and win every time (when Monty opens B, that it). If p=1, P(A|E) = 1/2, so in that case it doesn't matter whether you stick or switch.
When Monty opens C, P(A|E) = (1-p) / (2-p)
[Correction: the answer in this case is not (1-p) / (1+p), which what I wrote in a previous version of this article. Sorry!].
7) And finally, here is a new problem I just came up with:
If you meet a man with (naturally) red hair, what is the probability that neither of his parents has red hair?Hints: About 2% of the world population has red hair. You can assume that the alleles for red hair are purely recessive. Also, you can assume that the Red Hair Extinction theory is false, so you can apply the Hardy–Weinberg principle.
Solution to this one next week!
Please let me know if you have suggestions for more problems. An ideal problem should meet at least some of these criteria:
1) It should be based on a context that is realistic or at least interesting, and not too contrived.
2) It should make good use of Bayes's Theorem -- that is, it should be easier to solve with BT than without.
3) It should involve some real data, which the solver might have to find.
4) It might involve a trick, but should not be artificially hard.




