Survival analysis
Survival analysis is a way to describe how long things last. It is often used to study human lifetimes, but it also applies to “survival” of mechanical and electronic components, or more generally to intervals in time before an event.If someone you know has been diagnosed with a life-threatening disease, you might have seen a “5-year survival rate,” which is the probability of surviving five years after diagnosis. That estimate and related statistics are the result of survival analysis.
As a more cheerful example, I will use data from the National Survey of Family Growth (NSFG) to quantify how long respondents “survive” until they get married for the first time. The range of respondents’ ages is 14 to 44 years, so the dataset provides a snapshot of women at different stages in their lives, in the same way that a medical cohort might include patients at difference stages of disease.
For women who have been married, the dataset includes the date of their first marriage and their age at the time. For women who have not been married, we know their age when interviewed, but have no way of knowing when or if they will get married.
Since we know the age at first marriage for some women, it might be tempting to exclude the rest and compute the distribution of the known data. That is a bad idea. The result would be doubly misleading: (1) older women would be overrepresented, because they are more likely to be married when interviewed, and (2) married women would be overrepresented! In fact, this analysis would lead to the conclusion that all women get married, which is obviously incorrect.
Kaplan-Meier estimation
In this example it is not only desirable but necessary to include observations of unmarried women, which brings us to one of the central algorithms in survival analysis, Kaplan-Meier estimation.The general idea is that we can use the data to estimate the hazard function, then convert the hazard function to a survival function. To estimate the hazard function, we consider, for each age, (1) the number of women who got married at that age and (2) the number of women “at risk” of getting married, which includes all women who were not married at an earlier age.
The details of the algorithm are in the book; we'll skip to the results:

The top graph shows the estimated hazard function; it is low in the teens, higher in the 20s, and declining in the 30s. It increases again in the 40s, but that is an artifact of the estimation process; as the number of respondents “at risk” decreases, a small number of women getting married yields a large estimated hazard. The survival function will smooth out this noise.
The bottom graph shows the survival function, which shows for each age the fraction of people who are still unmarried at that age. The curve is steepest between 25 and 35, when most women get married. Between 35 and 45, the curve is nearly flat, indicating that women who do not marry before age 35 are unlikely to get married before age 45.
A curve like this was the basis of a famous magazine article in 1986; Newsweek reported that a 40-year old unmarried woman was “more likely to be killed by a terrorist” than get married. These statistics were widely reported and became part of popular culture, but they were wrong then (because they were based on faulty analysis) and turned out to be even more wrong (because of cultural changes that were already in progress and continued). In 2006, Newsweek ran an another article admitting that they were wrong.

I encourage you to read more about this article, the statistics it was based on, and the reaction. It should remind you of the ethical obligation to perform statistical analysis with care, interpret the results with appropriate skepticism, and present them to the public accurately and honestly.
Cohort effects
One of the challenges of survival analysis, and one of the reasons Newsweek was wrong, is that different parts of the estimated curve are based on different groups of respondents. The part of the curve at time t is based on respondents whose age was at least t when they were interviewed. So the leftmost part of the curve includes data from all respondents, but the rightmost part includes only the oldest respondents.If the relevant characteristics of the respondents are not changing over time, that’s fine, but in this case it seems likely that marriage patterns are different for women born in different generations. We can investigate this effect by grouping respondents according to their decade of birth. Groups like this, defined by date of birth or similar events, are called cohorts, and differences between the groups are called cohort effects.
To investigate cohort effects in the NSFG marriage data, I gathered Cycle 5 data from 1995, Cycle 6 data from 2002, the Cycle 7 data from 2006–2010. In total these datasets include 30,769 respondents.
I divided respondents into cohorts by decade of birth and estimated the survival curve for each cohort:

Several patterns are visible:
- Women born in the 50s married earliest, with successive cohorts marrying later and later, at least until age 30 or so.
- Women born in the 60s follow a surprising pattern. Prior to age 25, they were marrying at slower rates than their predecessors. After age 25, they were marrying faster. By age 32 they had overtaken the 50s cohort, and at age 44 they are substantially more likely to have married. Women born in the 60s turned 25 between 1985 and 1995. Remembering that the Newsweek article was published in 1986, it is tempting to imagine that the article triggered a marriage boom. That explanation would be too pat, but it is possible that the article and the reaction to it were indicative of a mood that affected the behavior of this cohort.
- The pattern of the 70s cohort is similar. They are less likely than their predecessors to be married before age 25, but at age 35 they have caught up with both of the previous cohorts.
- Women born in the 80s are even less likely to marry before age 25. What happens after that is not clear; for more data, we have to wait for the next cycle of the NSFG, coming in late fall 2014.
Expected remaining lifetime
Given a survival curve, we can compute the expected remaining lifetime as a function of current age. For example, given the survival function of pregnancy length, we can compute the expected time until delivery.For example, the following figure (left) shows the expecting remaining pregnancy length as a function of the current duration. During Week 0, the expected remaining duration is about 34 weeks. That’s less than full term (39 weeks) because terminations of pregnancy in the first trimester bring the average down.
The curve drops slowly during the first trimester: after 13 weeks, the expected remaining lifetime has dropped by only 9 weeks, to 25. After that the curve drops faster, by about a week per week.

Between Week 37 and 42, the curve levels off between 1 and 2 weeks. At any time during this period, the expected remaining lifetime is the same; with each week that passes, the destination gets no closer. Processes with this property are called “memoryless,” because the past has no effect on the predictions. This behavior is the mathematical basis of the infuriating mantra of obstetrics nurses: “any day now.”
The figure also shows the median remaining time until first marriage, as a function of age. For an 11 year-old girl, the median time until first marriage is about 14 years. The curve decreases until age 22 when the median remaining time is about 7 years. After that it increases again: by age 30 it is back where it started, at 14 years.
For the marriage data I used median rather than mean because the dataset includes women who are unmarried at age 44. The survival curve is cut off at about 20%, so we can't compute a mean. But the median is well defined as long as more than 50% of the remaining values are known.
Based on this data, young women have decreasing remaining "lifetimes". Mechanical components with this property are called NBUE for "new better than used in expectation," meaning that a new part is expected to last longer.
Women older than 22 have increasing remaining time until first marriage. Components with this property are UBNE for "used better than new in expectation." That is, the older the part, the longer it is expected to last. Newborns and cancer patients are also UBNE; their life expectancy increases the longer they live. Also, people learning to ride a motorcycle.
Details of the calculations in this article are in Think Stats, Chapter 13. The code is in survival.py.
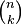 , and
, and 