Today Dennis Kimetto ran the Berlin Marathon in 2:02:57, shaving 26 seconds off the previous world record. That means it's time to check in on the world record progression and update my
update from last year of
my article from two years ago. The following is a revised version of that article, including the new data point.
Abstract: I propose a model that explains why world record progressions in running speed are improving linearly, and should continue as long as the population of potential runners grows exponentially. Based on recent marathon world records, I extrapolate that we will break the two-hour barrier in 2041.
-----
Let me start with the punchline:
The blue points show the progression of marathon records since 1970, including the new mark. The blue line is a least-squares fit to the data, and the red line is the target pace for a two-hour marathon, 13.1 mph. The blue line hits the target pace in 2041.
In general, linear extrapolation of a time series is a dubious business, but in this case I think it is justified:
1) The distribution of running speeds is not a bell curve. It has a long tail of athletes who are much faster than normal runners. Below I propose a model that explains this tail, and suggests that there is still room between the fastest human ever born and the fastest possible human.
2) I’m not just fitting a line to arbitrary data; there is theoretical reason to expect the progression of world records to be linear, which I present below. And since there is no evidence that the curve is starting to roll over, I think it is reasonable to expect it to continue for a while.
3) Finally, I am not extrapolating beyond reasonable human performance. The target pace for a two-hour marathon is 13.1 mph, which is slower than the current world record for the half marathon (58:23 minutes, or 13.5 mph). It is unlikely that the current top marathoners will be able to maintain this pace for two hours, but we have no reason to think that it is beyond theoretical human capability.
My model, and the data it is based on, are below.
-----
In April 2011, I collected the world record progression for running events of various distances and plotted speed versus year (
here's the data, mostly from Wikipedia). The following figure shows the results:
You might notice a pattern; for almost all of these events, the world record progression is a remarkably straight line. I am not the first person to notice, but as far as I know, no one has proposed an explanation for the shape of this curve.
Until now -- I think I know why these lines are straight. Here are the pieces:
1) Each person's potential is determined by several factors that are independent of each other; for example, your VO2 max and the springiness of your tendons are probably unrelated.
2) Each runner's overall potential is limited by their weakest factor. For example, if there are 10 factors, and you are really good at 9 of them, but below average on the 10th, you will probably not be a world-class runner.
3) As a result of (1) and (2), potential is not normally distributed; it is long-tailed. That is, most people are slow, but there are a few people who are much faster.
4) Runner development has the structure of a pipeline. At each stage, the fastest runners are selected to go on to the next stage.
5) If the same number of people went through the pipeline each year, the rate of new records would slow down quickly.
6) But the number of people in the pipeline actually grows exponentially.
7) As a result of (5) and (6) the rate of new records is linear.
8) This model suggests that linear improvement will continue as long as the world population grows exponentially.
Let's look at each of those pieces in detail:
Physiological factors that determine running potential include VO2 max, anaerobic capacity, height, body type, muscle mass and composition (fast and slow twitch),
conformation, bone strength, tendon elasticity, healing rate and probably more. Psychological factors include competitiveness, persistence, tolerance of pain and boredom, and focus.
Most of these factors have a large component that is inherent, they are mostly independent of each other, and any one of them can be a limiting factor. That is, if you are good at all of them, and bad at one, you will not be a world-class runner. To summarize: there is only one way to be fast, but there are a lot of ways to be slow.
As a simple model of these factors, we can generate a random person by picking N random numbers, where each number is normally-distributed under a logistic transform. This yields a bell-shaped distribution bounded between 0 and 1, where 0 represents the worst possible value (at least for purposes of running speed) and 1 represents the best possible value.
Then to represent the running potential of each person, we compute the minimum of these factors. Here's what the code looks like:
def GeneratePerson(n=10):
factors = [random.normalvariate(0.0, 1.0) for i in range(n)]
logs = [Logistic(x) for x in factors]
return min(logs)
Yes, that's right, I just reduced a person to a single number. Cue the humanities majors lamenting the blindness and arrogance of scientists. Then explain that this is supposed to be an explanatory model, so simplicity is a virtue. A model that is as rich and complex as the world is not a model.
Here's what the distribution of potential looks like for different values of N:
When N=1, there are many people near the maximum value. If we choose 100,000 people at random, we are likely to see someone near 98% of the limit. But as N increases, the probability of large values drops fast. For N=5, the fastest runner out of 100,000 is near 85%. For N=10, he is at 65%, and for N=50 only 33%.
In this kind of lottery, it takes a long time to hit the jackpot. And that's important, because it suggests that even after 7 billion people, we might not have seen anyone near the theoretical limit.
Let's see what effect this model has on the progression of world records. Imagine that we choose a million people and test them one at a time for running potential (and suppose that we have a perfect test). As we perform tests, we keep track of the fastest runner we have seen, and plot the "world record" as a function of the number of tests.
Here's the code:
def WorldRecord(m=100000, n=10):
data = []
best = 0.0
for i in xrange(m):
person = GeneratePerson(n)
if person > best:
best = person
data.append(i/m, best))
return data
And here are the results with M=100,000 people and the number of factors N=10:
The x-axis is the fraction of people we have tested. The y-axis is the potential of the best person we have seen so far. As expected, the world record increases quickly at first and then slows down.
In fact, the time between new records grows geometrically. To see why, consider this: if it took 100 people to set the current record, we expect it to take 100 more to exceed the record. Then after 200 people, it should take 200 more. After 400 people, 400 more, and so on. Since the time between new records grows geometrically, this curve is logarithmic.
So if we test the same number of people each year, the progression of world records is logarithmic, not linear. But if the number of tests per year grows exponentially, that's the same as plotting the previous results on a log scale. Here's what you get:
That's right: a log curve on a log scale is a straight line. And I believe that that's why world records behave the way they do.
This model is unrealistic in some obvious ways. We don't have a perfect test for running potential and we don't apply it to everyone. Not everyone with the potential to be a runner has the opportunity to develop that potential, and some with the opportunity choose not to.
But the pipeline that selects and trains runners behaves, in some ways, like the model. If a person with record-breaking potential is born in Kenya, where running is the national sport, the chances are good that he will be found, have opportunities to train, and become a world-class runner. It is not a certainty, but the chances are good.
If the same person is born in rural India, he may not have the opportunity to train; if he is in the United States, he might have options that are more appealing.
So in some sense the relevant population is not the world, but the people who are likely to become professional runners, given the talent. As long as this population is growing exponentially, world records will increase linearly.
That said, the slope of the line depends on the parameter of exponential growth. If economic development increases the fraction of people in the world who have the opportunity to become professional runners, these curves could accelerate.
So let's get back to the original question: when will a marathoner break the 2-hour barrier? Before 1970, marathon times improved quickly; since then the rate has slowed. But progress has been consistent for the last 40 years, with no sign of an impending asymptote. So I think it is reasonable to fit a line to recent data and extrapolate. Here are the results [based on 2011 data; see above for the update]:
The red line is the target: 13.1 mph. The blue line is a least squares fit to the data. So here's my prediction: there will be a 2-hour marathon in 2041. I'll be 76, so my chances of seeing it are pretty good. But that's a topic for another article (see
Chapter 1 of Think Bayes).














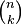 , and
, and 