Last fall I taught an introduction to Bayesian statistics at Olin College. My students worked on some excellent projects, and I invited them to write up their results as guest articles for this blog.
One of the teams applied Bayesian survival analysis to the characters in A Song of Ice and Fire, the book series by George R. R. Martin. Using data from the first 5 books, they generate predictions for which characters are likely to survive and which might die in the forthcoming books.
With Season 5 of the Game of Thrones television series starting on April 12, we thought this would be a good time to publish their report.
Bayesian Survival Analysis in A Song of Ice and Fire
Erin Pierce and Ben Kahle |
The Song of Ice and Fire series has a reputation for being quite deadly. No character, good or bad, major or minor is safe from Martin’s pen. The reputation is not unwarranted; of the 916 named characters that populate Martin’s world, a third have died, alongside uncounted nameless ones.
In this report, we take a closer look at the patterns of death in the novels and create a Bayesian model that predicts the probability that characters will survive the next two books.
Using data from A Wiki of Ice and Fire, we created a dataset of all 916 characters that appeared in the books so far. For every character, we know what chapter and book they first appeared, if they are male or female, if they are part of the nobility or not, what major house they are loyal to, and, if applicable, the chapter and book of their death. We used this data to predict which characters will survive the next couple books.
Methodology
We extrapolated the survival probabilities of the characters through the seventh book using Weibull distributions. A Weibull distribution provides a way to model the hazard function, which measures the probability of death at a specific age. The Weibull distribution depends on two parameters, k and lambda, which control its shape.
To estimate these parameters, we start with a uniform prior. For each alive character, we check how well that value of k or lambda predicted the fact that the character was still alive by comparing the calculated Weibull distribution with the character’s hazard function. For each dead character, we check how well the parameters predicted the time of their death by comparing the Weibull distribution with the character’s survival function.
The main code used to update these distributions is:
class GOT(thinkbayes2.Suite, thinkbayes2.Joint):
def Likelihood(self, data, hypo): """Determines how well a given k and lam
predict the life/death of a character """
age, alive = data
k, lam = hypo
if alive: prob = 1-exponweib.cdf(age, k, lam) else: prob = exponweib.pdf(age, k, lam) return prob def Update(k, lam, age, alive): """Performs the Baysian Update and returns the PMFs
of k and lam"""
joint = thinkbayes2.MakeJoint(k, lam) suite = GOT(joint) suite.Update((age, alive)) k = suite.Marginal(0, label=k.label),
lam = suite.Marginal(1, label=lam.label)
return k, lam def MakeDistr(introductions, lifetimes,k,lam): """Iterates through all the characters for a given k
and lambda. It then updates the k and lambda
distributions"""
k.label = 'K' lam.label = 'Lam' print("Updating deaths") for age in lifetimes: k, lam = Update(k, lam, age, False) print('Updating alives') for age in introductions: k, lam = Update(k, lam, age, True) return k,lam |
For the Night’s Watch, this lead to the posterior distribution in Figure 3.
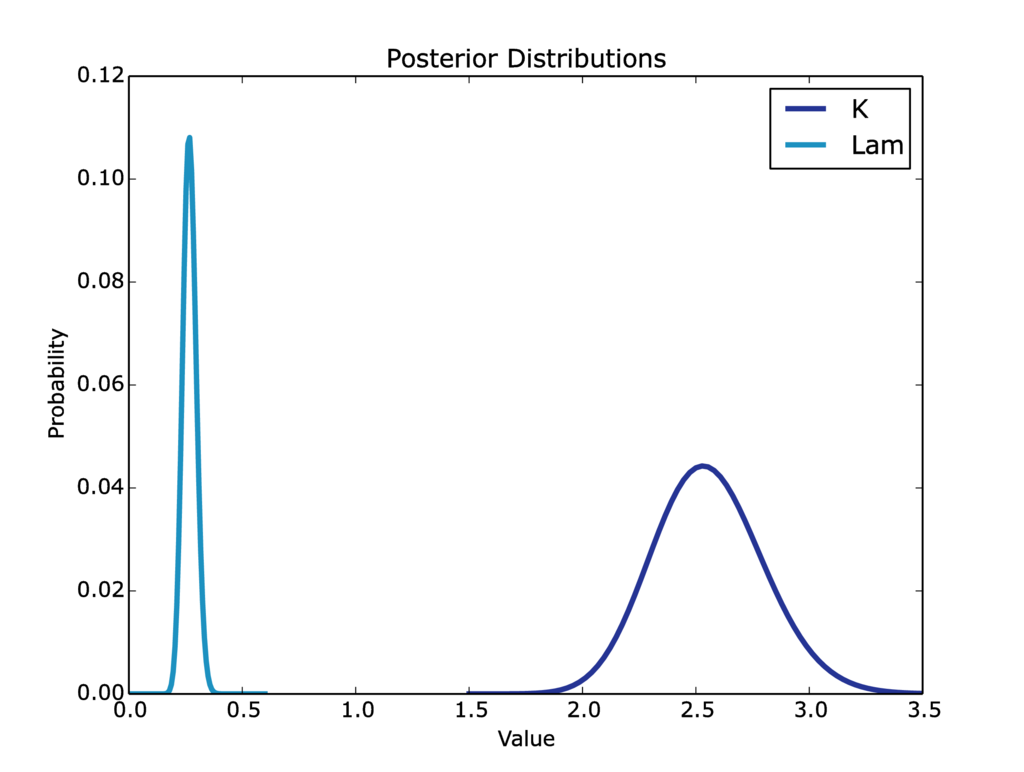
Figure 3: The distribution for lambda is quite tight, around 0.27, but the distribution for k is broader.
|
To translate this back to a survival curve, we took the mean of k and lambda, as well as the 90 percent credible interval for each parameter. We then plot the original data, the credible interval, and the survival curve based on the posterior means.
Jon Snow
Using this analysis, we can can begin to make a prediction for an individual character like Jon Snow. At the end of A Dance with Dragons, the credible interval for the Night’s Watch survival (Figure 4) stretches from 36 percent to 56 percent. The odds are not exactly rosy that Jon snow is still alive. Even if Jon is still alive at the end of book 5, the odds that he will survive the next two books drop to between 30 percent and 51 percent.
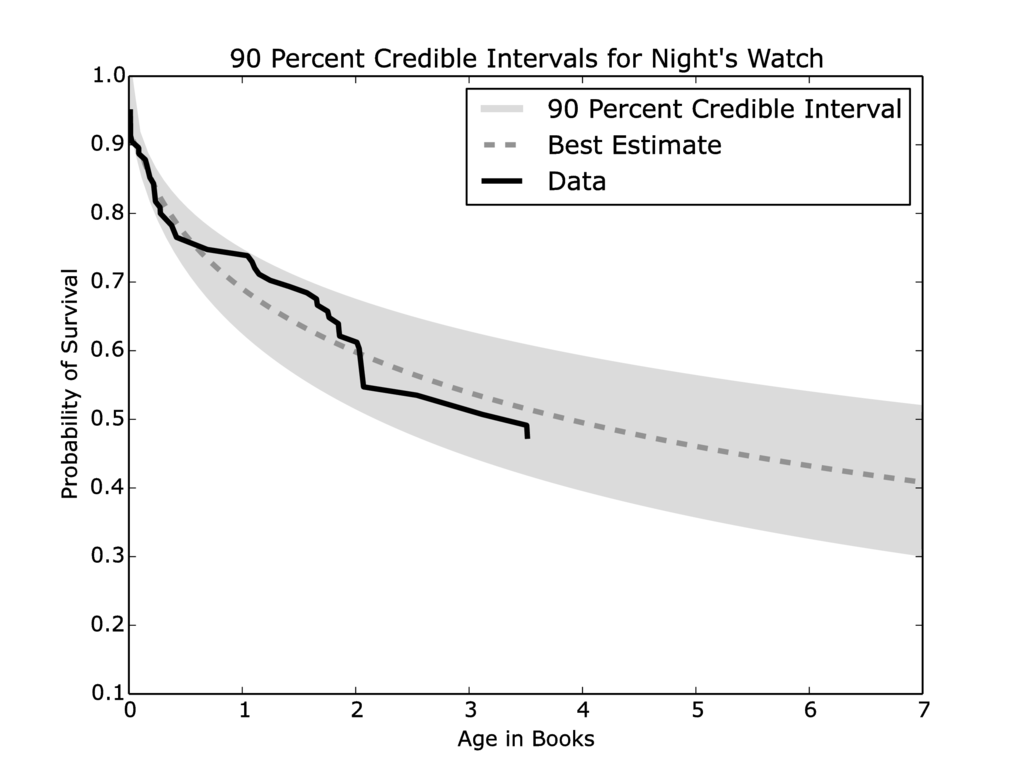
Figure 4: The credible interval closely encases the data, and the mean-value curve appears to be a reasonable approximation.
|
However, it is worth considering that Jon is not an average member of the Night’s Watch. He had a noble upbringing and is well trained at arms. We repeated the same analysis with only members of the Night’s Watch considered noble due to their family, rank, or upbringing.
There have only been 11 nobles in the Night’s Watch, so the credible interval as seen in Figure 5 is understandably much wider, however, the best approximation of the survival curve suggests that a noble background does not increase the survival rate for brothers of the Night’s Watch.
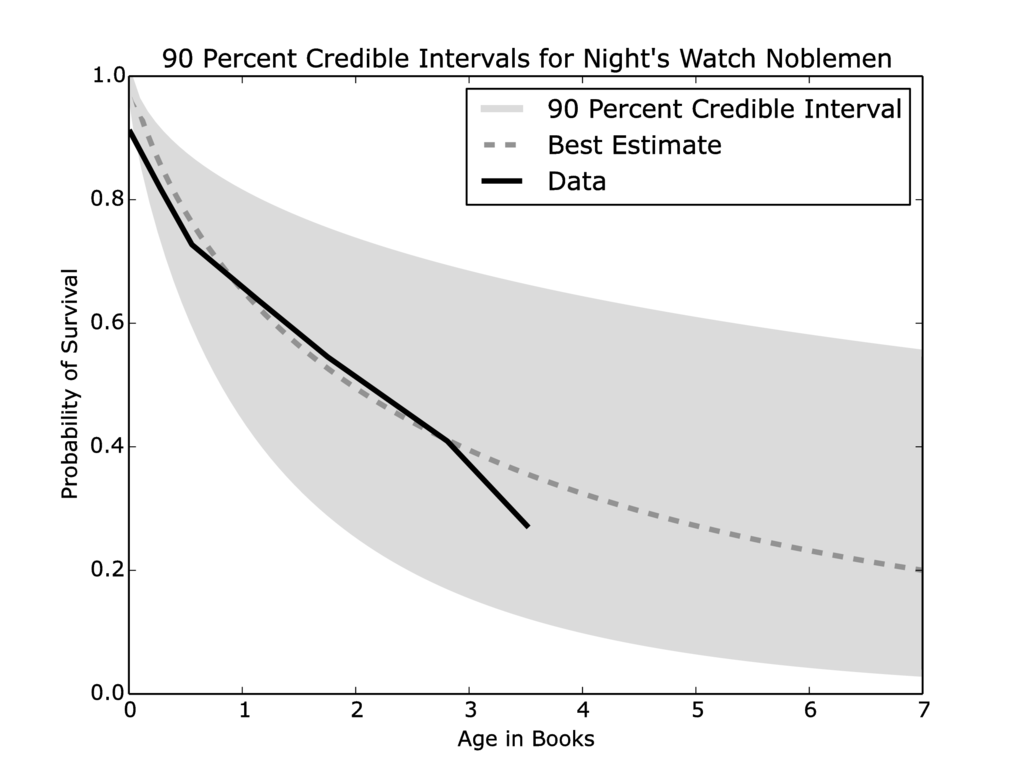
Figure 5: When only noble members of the Night’s Watch are included, the credible interval widens significantly and the lower bound gets quite close to zero.
|
The Houses of ASOIAF
The 90 percent credible intervals for all of the major houses. This includes the 9 major houses, the Night’s Watch, the Wildlings, and a "None" category which includes non-allied characters.
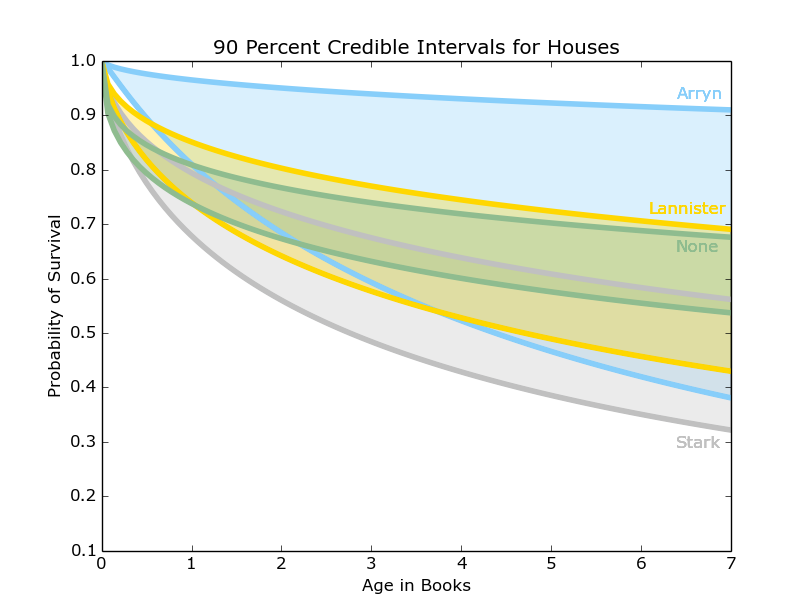
Figure 6: 90 percent credible interval for Arryn (Blue), Lannister (Gold), None (Green), and Stark (Grey)
|
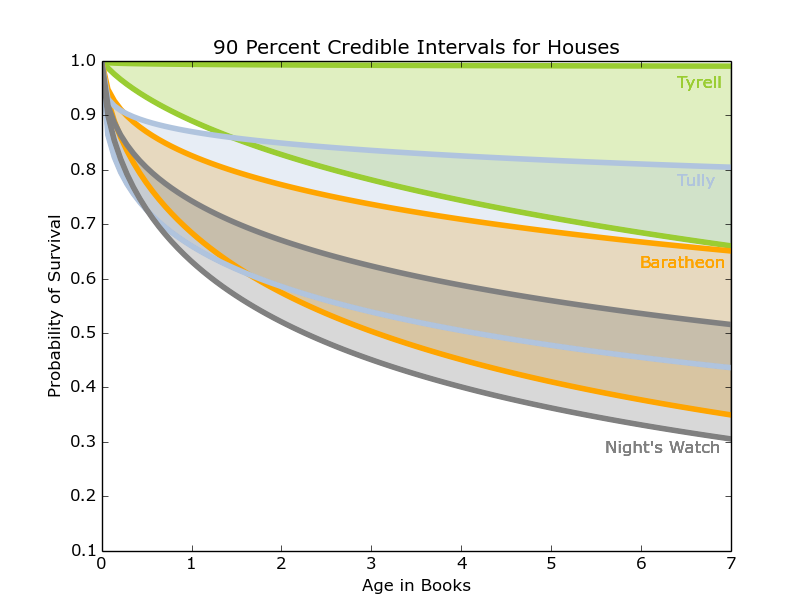
Figure 7: 90 percent credible interval for Tyrell(Green), Tully(Blue), Baratheon(Orange), and Night’s Watch (Grey)
|
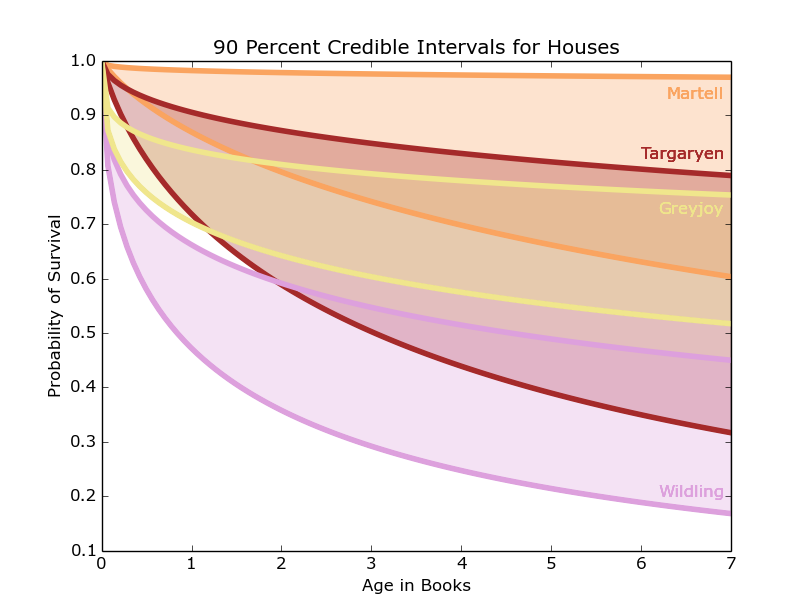
Figure 8: 90 percent credible interval for Martell(Orange), Targaryen (Maroon), Greyjoy (Yellow), and Wildling (Purple)
|
These intervals, shown in Figures 6, 7, and 8, demonstrate a much higher survival probability for the houses Arryn, Tyrell, and Martell. Supporting these results, these houses have stayed out of most of the major conflicts in the books, however this also means there is less information on them. We have 5 or fewer examples of dead members for those houses, so the survival curves don’t have very many points. This uncertainty is reflected in the wide credible intervals.
In contrast, our friends in the north, the Starks, Night’s Watch, and Wildlings have the lowest projected survival rates and smaller credible intervals given their warring positions in the story and the many important characters included amongst their ranks. This analysis considers entire houses, but there are also additional ways to sort the characters.
Men and women
While A Song of Ice and Fire has been lauded for portraying women as complex characters who take an a variety of roles, there are still many more male characters (769) than female ones (157). Despite a wider credible interval, the women tend to fare better than their male counterparts, out-surviving them by a wide margin as seen in Figure 9.
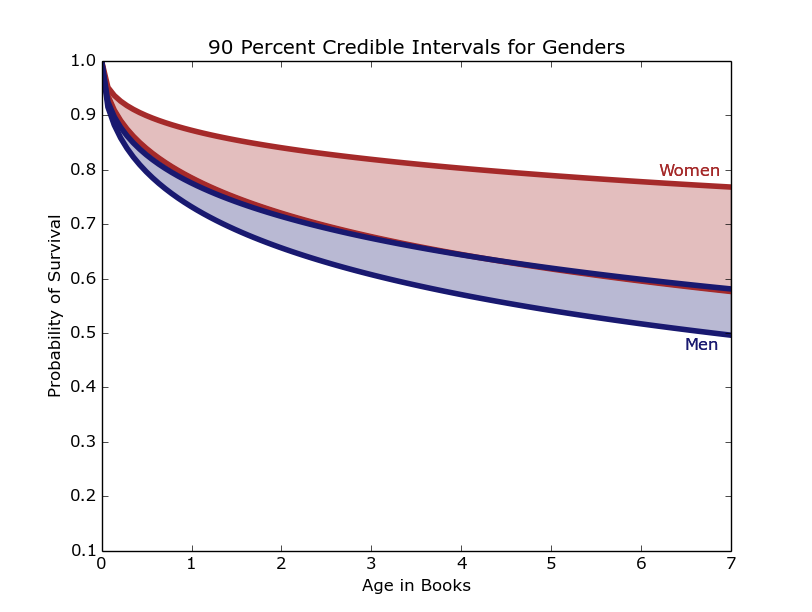
Figure 9: The women of Westeros appear to have a better chance of surviving then the men.
|
Class
The ratio between noble characters(429) and smallfolk characters (487) is much more even than gender and provides an interesting comparison for analysis. Figure 10 suggests that while more smallfolk tend to die quickly after being introduced, those that survive their introductions tend to live for a longer period of time and may in fact outpace the nobles.

Figure 10: The nobility might have a slight advantage when introduced, but their survival probability continues to fall while the smallfolk’s levels much more quickly
|
Selected Characters
The same analysis can be extended to combine traits, sorting by gender, house, and class to provide a rough model for individual characters. One of the most popular characters in the books is Arya and many readers are curious about her fate in the books to come. The category of noblewomen loyal to the Starks also includes other noteworthy characters like Sansa and Brienne of Tarth (though she was introduced later). Other intriguing characters to investigate are the Lannister noblewomen Cersei and poor Myrcella. As it turns out, not a lot noble women die. In order to get more precise credible intervals for the specific female characters we included the data of both noble and smallfolk women.
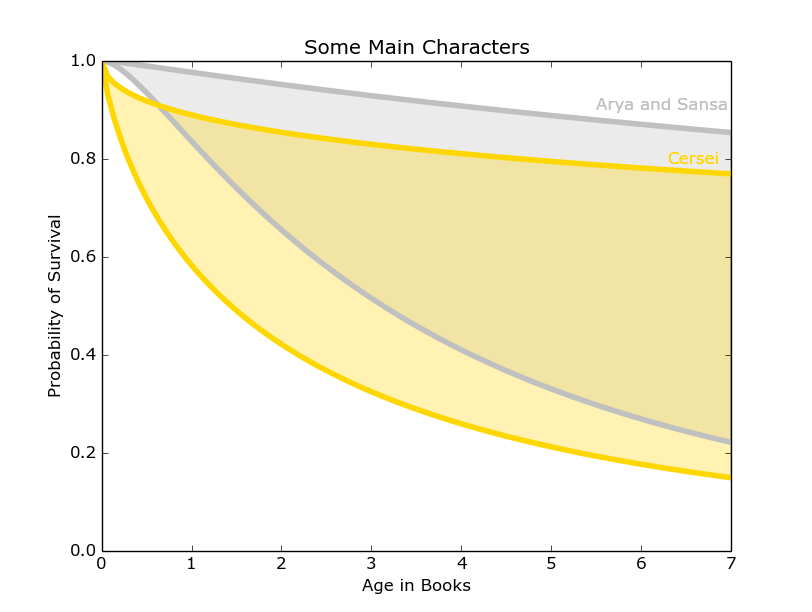
Figure 11: While both groups have very wide ranges of survival probabilities, the Lannister noblewomen may be a bit more likely to die than the Starks.
|
The data presented in Figure 11 is inconclusive, but it looks like Arya has a slightly better chance of survival than Cersei.
Two minor characters we are curious about are Val, the wildling princess, and the mysterious Quaithe.
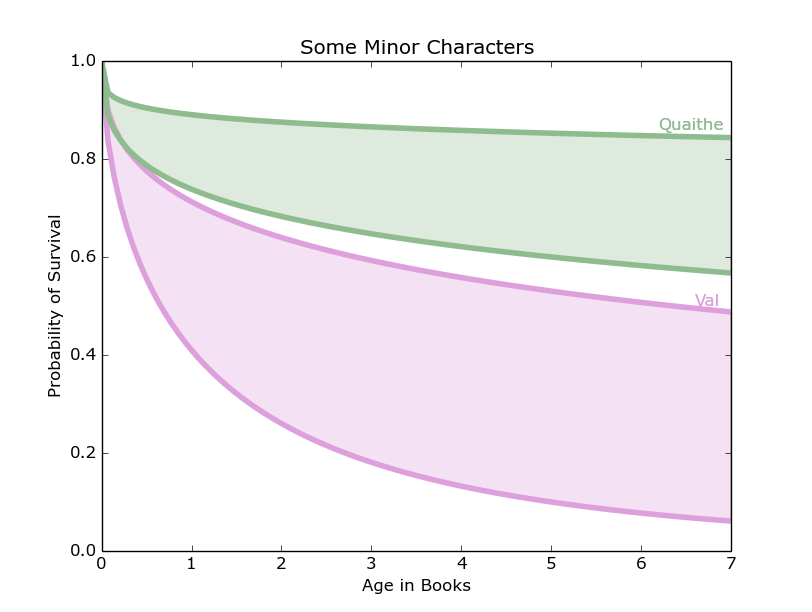
Figure 12: Representing the survival curves of more minor characters, Quaithe and Val have dramatically different odds of surviving the series.
|
They both had more data than the Starks and Lannisters, but they have the complication that they were not introduced at the beginning of the series. Val is introduced at 2.1 books, and so her chances of surviving the whole series are between 10 percent and 53 percent, which are not the most inspiring of chances.
Quaithe is introduced at 1.2 books, and her chances are between 58 percent and 85 percent, which are significantly better than Val’s. These curves are shown in Figure 12.
For most of the male characters (with the exception of Mance), there was enough data to narrow to house, gender and class.
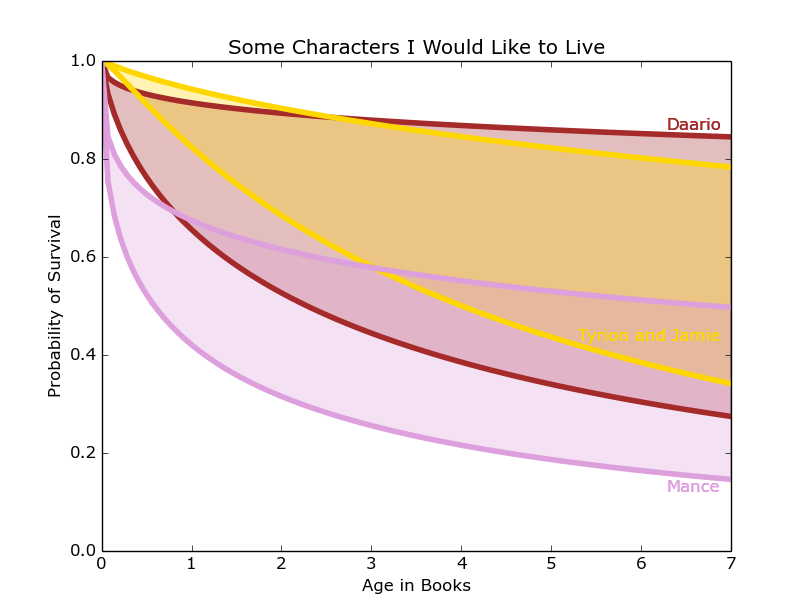
Figure 13: The survival curves of different classes and alliances of men shown through various characters.
|
Figure 13 shows the Lannister brothers with middling survival chances ranging from 35 percent to 79 percent. The data for Daario is less conclusive, but seems hopeful, especially considering he was introduced at 2.5 books. Mance seems to have to worst chance of surviving until the end. He was introduced at 2.2 books, giving him a chance of survival between 19 percent and 56 percent.
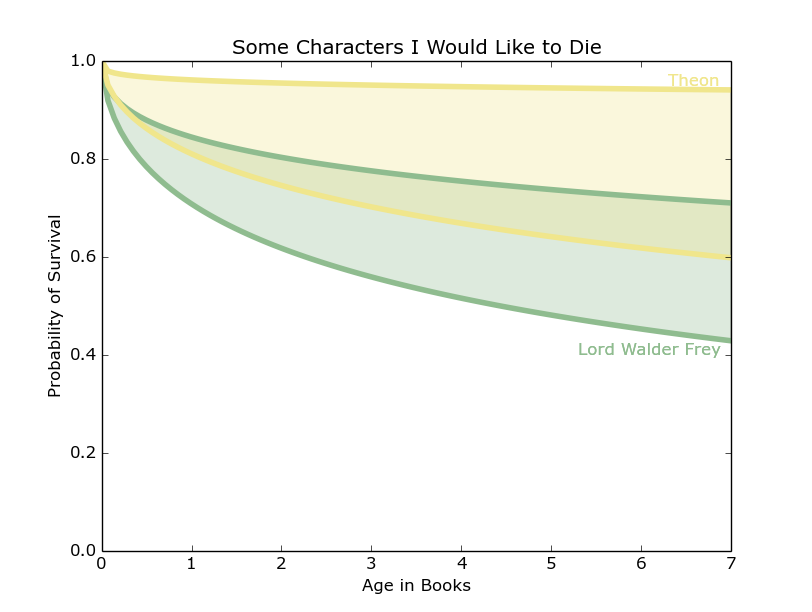
Figure 14: The survival curves of different classes and alliances of men shown through various characters.
|
Some characters who many wouldn’t mind seeing kick the bucket include Lord Walder Frey and Theon Greyjoy. However, Figure 14 suggests that neither are likely meet untimely (or in Walder Frey’s case, very timely) deaths. Theon seems likely to survive to the bitter end. Walder Frey was introduced at 0.4 books, putting his chances at 44 percent to 72 percent. As it is now, Hoster Tully may be the only character to die of old age, so perhaps Frey will hold out until the end.
Conclusion
Of course who lives and who dies in the next two books has more to do with plot and storyline than with statistics. Nonetheless, using our data we were able we were able to see patterns of life and death among groups of characters. For some characters, especially males, we are able to make specific predictions of how they will fare in the next novels. For females and characters from the less central houses, the verdict is still out.
Notes on the Data Set
Most characters were fairly easy to classify, but there are always edge cases.
- Gender - This was the most straight forward. There are not really any gender-ambigous characters.
- Nobility - Members of major and minor Westeros houses were counted as noble, but hedge knights were not. For characters from Essos, I used by best judgement based on money and power, and it was usually an easy call. For the wildlings, I named military leaders as noble, though that was often a blurry line. For members of the Night’s Watch, I looked at their status before joining in the same way I looked at other Westeros characters. For bastards, we decided on a case by case basis. Bastards who were raised in a noble family and who received the education and training of nobles were counted as noble. Thus Jon Snow was counted as noble, but someone like Gendry was not.
- Death - Characters that have come back alive-ish (like Beric Dondarrion) were judged dead at the time of their first death. Wights are not considered alive, but others are. For major characters whose deaths are uncertain, we argued and made a case by case decision.
- Houses - This was the trickiest one because some people have allegiances to multiple houses or have switched loyalties. We decided on a case by case basis. The people with no allegiance were of three main groups:
- People in Essos who are not loyal to the Targaryens.
- People in the Riverlands, either smallfolk whose loyalty is not known, or groups like the Brotherhood Without Banners or the Brave Companions with ambiguous loyalty.
- Nobility that are mostly looking out for their own interests, like the Freys, Ramsay Bolton, or Petyr Baelish.