About half of federal prisoners were convicted of drug crimes, according to this fact sheet from the US Sentencing Commission (USSC). In minimum security prisons, the proportion is higher, and in women's prisons, I would guess it is even higher. About 45% of federal prisoners were sentenced under mandatory minimum guidelines that sensible people would find shocking. And about a third of them had no prior criminal record, according to this report, also from the USSC.
In many cases, minor drug offenders are serving sentences much longer than sentences for serious violent crimes. For a list of heart-breaking examples, see these prisoner profiles at Families Against Mandatory Minimums.
Or watch this clip from Jon Oliver's Last Week Tonight:
When you are done being outraged, here are a few things to do:
1) Read more about Families Against Mandatory Minimums, write about them on social media, and consider making a donation (Charity Navigator gives them an excellent rating).
2) Another excellent source of information, and another group that deserves support, is the Prison Policy Initiative.
3) Then read the rest of this article, which points out that although Kerman's observations are fundamentally correct, her sampling process is biased in an interesting way.
The inspection paradox
It turns out that Kerman is the victim not just of a criminal justice system that is out of control, but also of a statistical error called the inspection paradox. I wrote about it in Chapter 3 of Think Stats, where I called it the Class Size Paradox, using the example of average class size.If you ask students how big their classes are, the average of their responses will be higher than the actual average, often substantially higher. And if you ask them how many children are in their families, the average of their responses will be higher than the average family size.
The problem is not the students, for once, but the sampling process. Large classes are overrepresented in the sample because in a large class there are more students to report a large class size. If there is a class with only one student, only one student will report that size.
And similarly with the number of children, large families are overrepresented and small families underrepresented; in fact, families with no children aren't represented at all.
The inspection paradox is an example of the Paradox Paradox, which is that a large majority of the things called paradoxes are not, actually, but just counter-intuitive truths. The apparent contradiction between the different averages is resolved when you realize that they are averages over different populations. One is the average in the population of classes; the other is the average in the population of student-class experiences.
Neither is right or wrong, but they are useful for different things. Teachers might care about the average size of the classes they teach; students might care more about the average of the classes they take.
Prison inspection
The same effect occurs if you visit a prison. Suppose you pick a random day, choose a prisoner at random, and ask the length of her sentence. The response is more likely to be a long sentence than a short one, because a prisoner with a long sentence has a better chance of being sampled. For each sentence duration, x, suppose the fraction of convicts given that sentence is p(x). In that case the probability of observing someone with that sentence is proportional to x p(x).Now imagine a different scenario: suppose you are serving an absurdly-long prison sentence, like 55 years for a minor drug offense. During that time you see prisoners with shorter sentences come and go, and if you keep track of their sentences, you get an unbiased view of the distribution of sentence lengths. So the probability of observing someone with sentence x is just p(x).
And that brings me to the question that occurred to me while I was reading Orange: what happens if you observe the system for a relatively short time, like Kerman's 11 months? Presumably the answer is somewhere between p(x) and x p(x). But where? And how does it depend on the length of the observer's sentence?
UPDATE 17 August 2015: A few days after I posted the original version of this article, Jerzy Wieczorek dropped by my office. Jerzy is an Olin alum who is now a grad student in statistics at CMU, so I posed this problem to him. A few days later he emailed me the solution, which is that the probability of observing a sentence, x, during and interval, t, is proportional to x + t. Couldn't be much simpler than that!
To see why, imagine a row of sentences arrange end-to-end along the number line. If you make an instantaneous observation, that's like throwing a dart at the number line. You chance of hitting a sentence with length x is (again) proportional to x.
Now imagine that instead of throwing a dart, you throw a piece of spaghetti with length t. What is the chance that the spaghetti overlaps with a sentence of length x? If we say arbitrarily that the sentence runs from 0 to x, the spaghetti will overlap the sentence if the left side falls anywhere between -t and x. So the size of the target is x + t.
Based on this result, here's a Python function that takes the actual PMF and returns a biased PMF as seen by someone serving a sentence with duration t:
def bias_pmf(pmf, t=0):
new_pmf = pmf.Copy()
for x, p in pmf.Items():
new_pmf[x] *= (x + t)
new_pmf.Normalize()
return new_pmf
This IPython notebook has the details, and here's a summary of the results.
Results
To model the distribution of sentences, I use random values from a gamma distribution, rounded to the nearest integer. All sentences are in units of months. I chose parameters that very roughly match the histogram of sentences reported by the USSC.The following code generates a sample of sentences as observed by a series of random arrivals. The notebook explains how it works.
sentences = np.random.gamma(shape=2, scale=60, size=1000).astype(int)
releases = sentences.cumsum()
arrivals = np.random.random_integers(1, releases[-1], 10000)
prisoners = releases.searchsorted(arrivals)
sample = sentences[prisoners]
cdf2 = thinkstats2.Cdf(sample, label='biased')
The following figure shows the actual distribution of sentences (that is, the model I chose), and the biased distribution as would be seen by random arrivals:
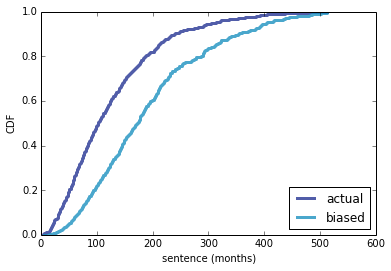
The following function simulates the observations of a person serving a sentence of t months. Again, the notebook explains how it works:
def simulate_sentence(sentences, t):
counter = Counter()
releases = sentences.cumsum()
last_release = releases[-1]
arrival = np.random.random_integers(1, max(sentences))
for i in range(arrival, last_release-t, 100):
first_prisoner = releases.searchsorted(i)
last_prisoner = releases.searchsorted(i+t)
observed_sentences = sentences[first_prisoner:last_prisoner+1]
counter.update(observed_sentences)
print(sum(counter.values()))
return thinkstats2.Cdf(counter, label='observed %d' % t)
Here's the distribution of sentences as seen by someone serving 11 months, as Kerman did:

The observed distribution is almost as biased as what would be seen by an instantaneous observer. Even after 120 months (near the average sentence), the observed distribution is substantially biased:


No comments:
Post a Comment