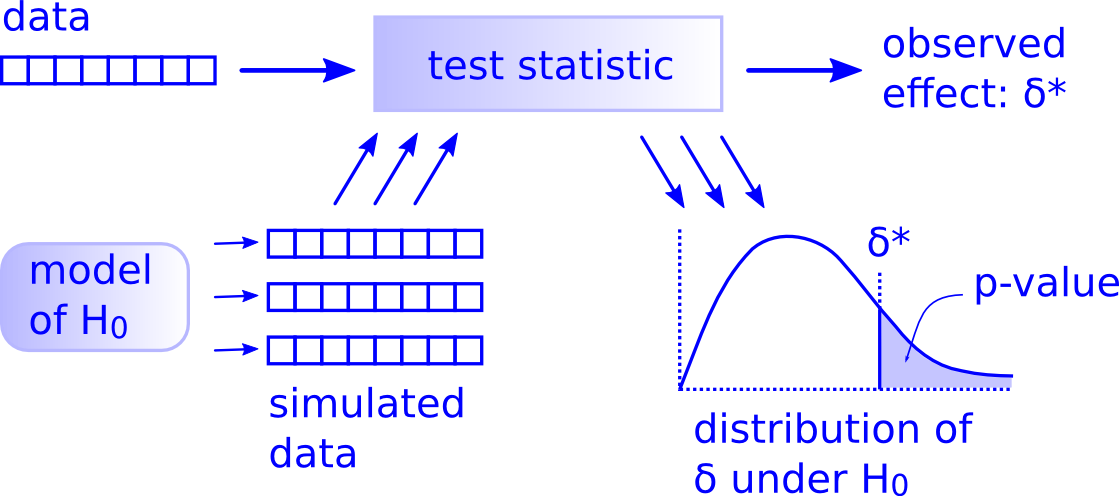
1) Given a dataset, you compute a test statistic that measures the size of the apparent effect. For example, if you are describing a difference between two groups, the test statistic might be the absolute difference in means. I'll call the test statistic from the observed data 𝛿*.
2) Next, you define a null hypothesis, which is a model of the world under the assumption that the effect is not real; for example, if you think there might be a difference between two groups, the null hypothesis would assume that there is no difference.
3) Your model of the null hypothesis should be stochastic; that is, capable of generating random datasets similar to the original dataset.
4) Now, the goal of classical hypothesis testing is to compute a p-value, which is the probability of seeing an effect as big as 𝛿* under the null hypothesis. You can estimate the p-value by using your model of the null hypothesis to generate many simulated datasets. For each simulated dataset, compute the same test statistic you used on the actual data.
5) Finally, count the fraction of times the test statistic from simulated data exceeds 𝛿*. This fraction approximates the p-value. If it's sufficiently small, you can conclude that the apparent effect is unlikely to be due to chance (if you don't believe that sentence, please read this).
That's it. All hypothesis tests fit into this framework. The reason there are so many names for so many supposedly different tests is that each name corresponds to
1) A test statistic,
2) A model of a null hypothesis, and usually,
3) An analytic method that computes or approximates the p-value.
These analytic methods were necessary when computation was slow and expensive, but as computation gets cheaper and faster, they are less appealing because:
1) They are inflexible: If you use a standard test you are committed to using a particular test statistic and a particular model of the null hypothesis. You might have to use a test statistic that is not appropriate for your problem domain, only because it lends itself to analysis. And if the problem you are trying to solve doesn't fit an off-the-shelf model, you are out of luck.
2) They are opaque: The null hypothesis is a model, which means it is a simplification of the world. For any real-world scenario, there are many possible models, based on different assumptions. In most standard tests, these assumptions are implicit, and it is not easy to know whether a model is appropriate for a particular scenario.
One of the most important advantages of simulation methods is that they make the model explicit. When you create a simulation, you are forced to think about your modeling decisions, and the simulations themselves document those decisions.
And simulations are almost arbitrarily flexible. It is easy to try out several test statistics and several models, so you can choose the ones most appropriate for the scenario. And if different models yield very different results, that's a useful warning that the results are open to interpretation. (Here's an example I wrote about in 2011.)
More resources
A few days ago, I saw this discussion on Reddit. In response to the question "Looking back on what you know so far, what statistical concept took you a surprising amount of effort to understand?", one redditor wroteThe general logic behind statistical tests and null hypothesis testing took quite some time for me. I was doing t-tests and the like in both work and classes at that time, but the overall picture evaded me for some reason.
I remember the exact time where everything started clicking - that was after I found a blog post (cannot find it now) called something like "There is only one statistical test". And it explained the general logic of testing something and tied it down to permutations. All of that seemed very natural.I am pretty sure they were talking about my article. How nice! In response, I provided links to some additional resources; and I'll post them here, too.
First, I wrote a followup to my original article, called "More hypotheses, less trivia", where I provided more concrete examples using the simulation framework.
Later in 2011 I did a webcast with O'Reilly Media where I explained the whole idea:
In 2015 I developed a workshop called "Computational Statistics", where I present this framework along with a similar computational framework for computing confidence intervals. The slides and other materials from the workshop are here.
And I am not alone! In 2014, John Rauser presented a keynote address at Strata+Hadoop, with the excellent title "Statistics Without the Agonizing Pain":
And for several years, Jake VanderPlas has been banging a similar drum, most recently in an excellent talk at PyCon 2016:
UPDATE: John Rauser pointed me to this excellent article, "The Introductory Statistics Course: A Ptolemaic Curriculum" by George W. Cobb.
UPDATE: Andrew Bray has developed an R package called "infer" to do computational statistical inference. Here's an excellent talk where he explains it.
This is amazing stuff. Similar conclusions have been made about different equations: you just simulate them instead of trying to solve them. And in mechanical engineering, you learn all kinds of methods, but then in the real world, you just learn how to use numerical methods (fundamentally based on D.E.s). Even in the idealized world of electrical engineering, there is finally a push in recent years to go "full spice" (having numerical methods more readily available). Although in mechanical and electrical, generalized concepts in the brain is required to zero in on designs that are most likely to be the most efficient, then switching over to the numerical methods to work out the details. I wonder if there is a similar process needed here.
ReplyDeleteIt makes me wonder if physics and math are just compression methods suited for the brain. I mean they actually a priori *are*, but I wonder if they may not have any deeper significance than simply being something like patterns that are "accidentally" more common as a result of deeper, simpler logic rules with less K-complexity like cellular automata (Wolfram). And that the most efficient designs would be discoverable with quantum computing, in some way related to how it can break cryptography.
Yes! We take a similar approach here in a class called Modeling and Simulation, where we use MATLAB's ode45 function to solve differential equations. That gives students the ability to develop models of physical systems that include realistic factors, like friction and air resistance, that are out of scope in a class that is limited to analytic methods.
DeleteAnd I am very interested in the other idea you raise, how to do engineering design on systems that don't lend themselves to mathematical analysis. Do we have to search enormous design spaces? Or can we grow/evolve solutions?
In a somewhat similar vein, I'm quite fond of McElreath's recent Statistical Rethinking book and lecture videos:
ReplyDeletehttp://xcelab.net/rm/statistical-rethinking/
Yes, me too! Thanks for the link.
DeleteI think there was some other place where I found an explanation that there are two approaches to hypothesis validation. One used p-values. The other one was something like precision and recall (false positives and negatives) or something similar. I think it mentioned some disagreement between statisticians before p-values became popular. May this be possible?
ReplyDeleteThere was disagreement among statisticians about how to do hypothesis testing; what we ended up with is actually a weird hybrid that makes less sense than the alternatives. See https://en.wikipedia.org/wiki/Statistical_hypothesis_testing#Origins_and_early_controversy
DeleteRegarding precision and recall, those are the terms most often used in the context of information retrieval. In the context of stats, it's usually false positives and false negatives (or type I and type II errors). And in the context of machine learning, it's usually a confusion matrix. But they are all representations of the same information.